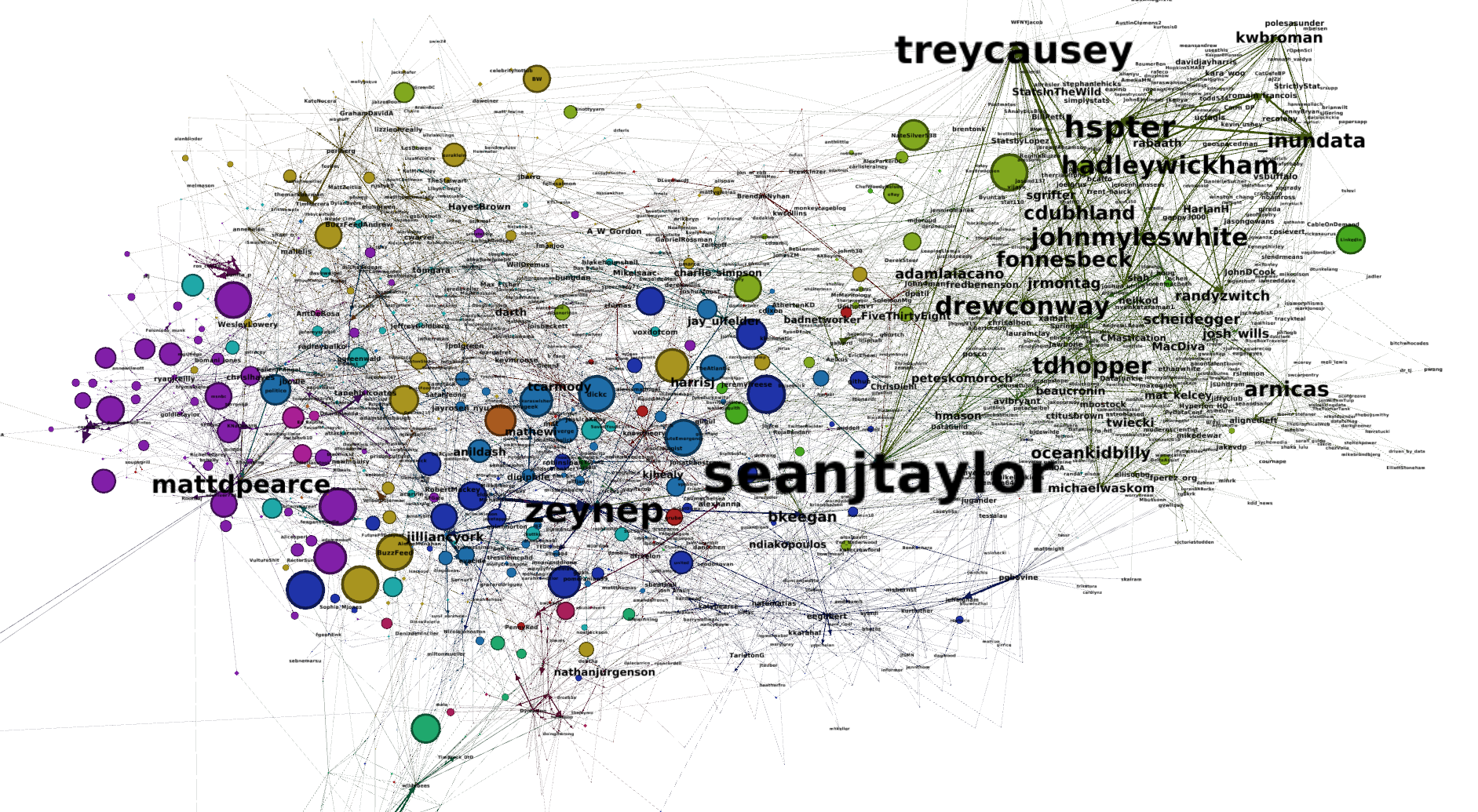
I’m still pondering the most recent Tufekci piece about algorithms and human judgment on Twitter. It prompted some grumbling among data scientists. Sweeping statements about ‘algorithms’ do that, since to a computer scientist ‘algorithm’ is about as general a term as ‘math’.
In later conversation, Tufekci clarified that when she was calling out the potential problems of algorithmic filtering of the Twitter newsfeed, she was speaking to the problems of a newsfeed curated algorithmically for the sake of maximizing ‘engagement’. Or ads. Or, it is apparent on a re-reading of the piece, new members. She thinks an anti-homophily algorithm would maybe be a good idea, but that this is so unlikely according to the commercial logic of Twitter to be a marginal point. And, meanwhile, she defends ‘human prioritizatin’ over algorithmic curation, despite the fact that homophily (not to mention preferential attachment) are arguable negative consequences of social system driven by human judgment.
I think inquiry into this question is important, but bound to be confusing to those who aren’t familiar in a deep way with network science, machine learning, and related fields. It’s also, I believe, helpful to have a background in cognitive science, because that’s a field which maintains that human judgment and computational systems are doing fundamentally commensurable kinds of work. When we think in sophisticated way about crowdsourced labor, we use this sort of thinking. We acknowledge, for example, that human brains are better at the computational task of image recognition, so then we employ Turkers to look at and label images. But those human judgments are then inputs to statistical processes that verify and check those judgments against each other. Later, those determinations that result from a combination of human judgment and algorithmic processing could be used in a search engine–which returns answers to questions based on human input. Search engines, then, are also a way of combining human and purely algorithmic judgment.
What it comes down to is that virtually all of our interactions with the internet are built around algorithmic affordances. And these systems can be understood systematically if we reject the quantitative/qualitative divide at the ontological level. Reductive physicalism entails this rejection, but–and this is not to be understated–pisses or alienates people who do qualitative or humanities research.
It’s I guess not surprising that STS and cultural studies academics are still around and in opposition to the hard scientists. What’s maybe new is how much computer science now affects the public, and how the popular press appears to have allied itself with the STS and cultural studies view. I guess this must be because cultural anthropologists and media studies people are more likely to become journalists and writers, whereas harder science is pretty abstruse.
There’s an interesting conflation now from the soft side of the culture wars of science with power/privilege/capitalism that plays out again and again. I bump into it in the university context. I read about it all the time. Tufekci’s pessimism that the only algorithmic filtering Twitter would adopt would be one that essentially obeys the logic “of Wall Street” is, well, sad. It’s sad that an unfortunate pairing that is analytically contingent is historically determined to be so.
But there is also something deeply wrong about this view. Of course there are humanitarian scientists. Of course there is a nuanced center to the science wars “debate”. It’s just that the tedious framing of the science wars has been so pervasive and compelling, like a commercial jingle, that it’s hard to feel like there’s an audience for anything more subtle. How would you even talk about it?
* I need to confess: I think there was some sloppiness in that Medium piece. If I had had more time, I would have done something to check which conversations were actually about the Tufekci article, and which were just about whatever. I feel I may have misrepresented this in the post. For the sake of accessibility or to make the point, I guess. Also, I’m retrospectively skittish about exactly how distinct a cluster the data scientists were, and whether its insularity might have been an artifact of the data collection method. I’ve been building out poll.emic in fits mainly as a hobby. I built it originally because I wanted to at last understand Weird Twitter’s internal structure. The results were interesting but I never got to writing them up. Now I’m afraid that the culture has changed so much that I wouldn’t recognize it any more. But I digress. Is it even notable that social scientists from different disciplines would have very different social circles around them? Is the generalization too much? And are there enough nodes in this graph to make it a significant thing to say about anything, really? There could be thousands of academic tiffs I haven’t heard about that are just as important but which defy my expectations and assumptions. Or is the fact that Medium appears to have endorsed a particular small set of public intellectuals significant? How many Medium readers are there? Not as many as there are Twitter users, by several orders of magnitude, I expect. Who matters? Do academics matter? Why am I even studying these people as opposed to people who do more real things? What about all the presumably sane and happy people who are not pathologically on the Internet? Etc.
I’ve been thinking over Robin James’ “Big Data & the ‘Physics’ of Social Harmony“, an essay in three sections. The first discusses Singapore’s use of data science to detect terrorists and public health threats for the sake of “social harmony,” as reported by Harris in Foreign Policy. The second ties together Plato, Pentland’s “social physics”, and neoliberalism. The last discusses the limits to individual liberty proposed by J.S. Mill. The author admits it’s “all over the place.” I get the sense that it is a draft towards a greater argument. It is very thought-provoking and informative.
I take issue with a number of points in the essay. Underlying my disagreement is what I think is a political difference about the framing of “data science” and its impact on society. Since I am a data science practitioner who takes my work seriously, I would like this framing to be nuanced, recognizing both the harm and help that data science can do. I would like the debate about data science to be more concrete and pragmatic so that practitioners can use this discussion as a guide to do the right thing. I believe this will require discussion of data science in society to be informed by a technical understanding of what data science is up to. However, I think it’s also very important that these discussions rigorously take up the normative questions surrounding data sciences’ use. It’s with this agenda that I’m interested in James’ piece.
James is a professor of Philosophy and Women’s/Gender Studies and the essay bears the hallmarks of these disciplines. Situated in a Western and primarily anglophone intellectual tradition, it draws on Plato and Mill for its understanding of social harmony and liberalism. At the same time, it has the political orientation common to Gender Studies, alluding to the gendered division of economic labor, at times adopting Marxist terminology, and holding suspicion for authoritarian power. Plato is read as being the intellectual root of a “particular neoliberal kind of social harmony” that is “the ideal that informs data science.” James contrasts this ideal with the ideal of individual liberty, as espoused and then limited by Mill.
Where I take issue with James is that I think this line of argument is biased by its disciplinary formation. (Since this is more or less a truism for all academics, I suppose this is less a rebuttal than a critique.) Where I believe this is most visible is in her casting of Singapore’s ideal of social harmony as an upgrade of Plato, via the ideology of neoliberalism. She does not not consider in the essay that Singapore’s ideal of social harmony might be rooted in Eastern philosophy, not Western philosophy. Though I have no special access or insight into the political philosophy of Singapore, this seems to me to be an important omission given that Singapore is ethnically 74.2% Chinese and with Buddhist plurality.
Social harmony is a central concept in Eastern, especially Chinese, philosophy with deep roots in Confucianism and Daoism. A great introduction for those with background in Western philosophy who are interested in the philosophical contributions of Confucius is Fingarette’s Confucius: The Secular as Sacred. Fingarette discusses how Confucian thought is a reaction to the social upheaval and war of Anciant China’s Warring States Period, roughly 475 – 221 BC. Out of these troubling social conditions, Confucian thought attempts to establish conditions for peace. These include ritualized forms of social interaction at whose center is a benevolent Emperor.
There are many parallels with Plato’s political philosophy, but Fingarette makes a point of highlighting where Confucianism is different. In particular, the role of social ritual and ceremony as the basis of society is at odds with Western individualism. Political power is not a matter of contest of wills but the proper enactment of communal rites. It is like a dance. Frequently, the word “harmony” is used in the translation of Confucian texts to refer to the ideal of this functional, peaceful ceremonial society and, especially, its relationship with nature.
A thorough analysis of use of data science for social control in light of Eastern philosophy would be an important and interesting work. I certainly haven’t done it. My point is simply that when we consider the use of data science for social control as a global phenomenon, it is dubious to see it narrowly in light of Western intellectual history and ideology. That includes rooting it in Plato, contrasting it with Mill, and characterizing it primarily as an expression of white neoliberalism. Expansive use of these Western tropes is a projection, a fallacy of “I think this way, therefore the world must.” This I submit is an occupational hazard of anyone who sees their work primarily as an analysis of critique of ideology.
In a lecture in 1965 printed in Knowledge and Human Interests, Habermas states:
The concept of knowledge-constitutive human interests already conjoins the two elements whose relation still has to be explained: knowledge and interest. From everyday experience we know that ideas serve often enough to furnish our actions with justifying motives in place of the real ones. What is called rationalization at this level is called ideology at the level of collective action. In both cases the manifest content of statements is falsified by consciousness’ unreflected tie to interests, despite its illusion of autonomy. The discipline of trained thought thus correctly aims at excluding such interests. In all the sciences routines have been developed that guard against the subjectivity of opinion, and a new discipline, the sociology of knowledge, has emerged to counter the uncontrolled influence of interests on a deeper level, which derive less from the individual than from the objective situation of social groups.
Habermas goes on to reflect on the interests driving scientific inquiry–“scientific” in the broadest sense of having to do with knowledge. He delineates:
Technical inquiry motivated by the drive for manipulation and control, or power
Historical-hermeneutic inquiry motivated by the drive to guide collective action
Critical, reflexive inquiry into how the objective situation of social groups controls ideology, motivated by the drive to be free or liberated
This was written in 1965. Habermas was positioning himself as a critical thinker; however, unlike some of the earlier Frankfurt School thinkers he drew on, he did maintained that technical power was an objective human interest. (see Bohman and Rehg) In the United States especially, criticality as a mode of inquiry took aim at the ideologies that aimed at white, bourgeois, and male power. Contemporary academic critique has since solidified as an academic discipline and wields political power. In particular, is frequently enlisted as an expression of the interests of marginalized groups. In so doing, academic criticality has (in my view regrettably) becomes mere ideology. No longer interested in being scientifically disinterested, it has become a tool of rationalization. It’s project is the articulation of changing historical conditions in certain institutionally recognized tropes. One of these tropes is the critique of capitalism, modernism, neoliberalism, etc. and their white male bourgeois heritage. Another is the feminist emphasis on domesticity as a dismissed form on economic production. This trope features in James’ analysis of Singapore’s ideal of social harmony:
Harris emphasizes that Singaporeans generally think that finely-tuned social harmony is the one thing that keeps the tiny city-state from tumbling into chaos. [1] In a context where resources are extremely scarce–there’s very little land, and little to no domestic water, food, or energy sources, harmony is crucial. It’s what makes society sufficiently productive so that it can generate enough commercial and tax revenue to buy and import the things it can’t cultivate domestically (and by domestically, I really mean domestically, as in, by ‘housework’ or the un/low-waged labor traditionally done by women and slaves/servants.) Harmony is what makes commercial processes efficient enough to make up for what’s lost when you don’t have a ‘domestic’ supply chain. (emphasis mine)
To me, this parenthetical is quite odd. There are other uses of the word “domestic” that do not specifically carry the connotation of women and slave/servants. For example, the economic idea of gross domestic product just means “an aggregate measure of production equal to the sum of the gross values added of all resident institutional units engaged in production (plus any taxes, and minus any subsidies, on products not included in the value of their outputs).” Included in that production is work done by men and high-wage laborers. To suggest that natural resources are primarily exploited by “domestic” labor in the ‘housework’ sense is bizarre given, say, agribusiness, industrial mining, etc.
There is perhaps an interesting etymological relationship here; does our use of ‘domestic’ in ‘domestic product’ have its roots in household production? I wouldn’t know. Does that same etymological root apply in Singapore? Was agriculture in East Asia traditionally the province of household servants in China and Southeast Asia (as opposed to independent farmers and their sons?)? Regardless, domestic economic production agricultural production is not housework now. So it’s mysterious that this detail should play a role in explaining Singapore’s emphasis on social harmony today.
So I think it’s safe to say that this parenthetical remark by James is due to her disciplinary orientation and academic focus. Perhaps it is a contortion to satisfy the audience of Cyborgology, which has a critical left-leaning politics. A Harris’s original article does not appear to support this interpretation. Rather, it only uses the word ‘harmony’ twice, and maintains a cultural sensitivity that James’ piece lacks, noting that Singapore’s use of data science may be motivated by a cultural fear of loss or risk.
The colloquial word kiasu, which stems from a vernacular Chinese word that means “fear of losing,” is a shorthand by which natives concisely convey the sense of vulnerability that seems coded into their social DNA (as well as their anxiety about missing out — on the best schools, the best jobs, the best new consumer products). Singaporeans’ boundless ambition is matched only by their extreme aversion to risk.
If we think that Harris is closer to the source here, then we do not need the projections of Western philosophy and neoliberal theory to explain what is really meant by Singapore’s use of data science. Rather, we can look to Singapore’s culture and perhaps its ideological origins in East Asian thinking. Confucius, not Plato.
* * *
If there it is a disciplinary bias to American philosophy departments, it is that they exist to reproduce anglophone philosophy. This is point that James has recently expressed herself…in fact while I have been in the process of writing this response.
I think I just had my "yeah maybe I don't belong in a philosophy department anymore" moment.
Though I don’t share James’ political project, generally speaking I agree that effort spent of the reproduction of disciplinary terminology is not helpful to the philosophical and scientific projects. Terminology should be deployed for pragmatic reasons in service to objective interests like power, understanding, and freedom. On the other hand, language requires consistency to be effective, and education requires language. My own personal conclusion on is that the scientific project can only be sustained now through disciplinary collapse.
When James suggests that old terms like metaphysics and epistemology prevent the de-centering of the “white supremacist/patriarchal/capitalist heart of philosophy”, she perhaps alludes to her recent coinage of “epistemontology” as a combination of epistemology and ontology, as a way of designating what neoliberalism is. She notes that she is trying to understand neoliberalism as an ideology, not as a historical period, and finds useful the definition that “neoliberals think everything in the universe works like a deregulated, competitive, financialized capitalist market.”
However helpful a philosophical understanding of neoliberalism as market epistemontology might be, I wonder whether James sees the tension between her statements about rejecting traditional terminology that reproduces the philosophical discipline and her interest in preserving the idea of “neoliberalism” in a way that can be be taught in an introduction to philosophy class, a point she makes in a blog comment later. It is, perhaps, in the act of teaching that a discipline is reproduced.
The use of neoliberalism as a target of leftist academic critique has been challenged relatively recently. Craig Hickman, in a blog post about Luis Suarez-Villa, writes:
In fact Williams and Srinicek see this already in their first statement in the interview where they remind us that “what is interesting is that the neoliberal hegemony remains relatively impervious to critique from the standpoint of the latter, whilst it appears fundamentally unable to counter a politics which would be able to combat it on the terrain of modernity, technology, creativity, and innovation.” That’s because the ball has moved and the neoliberalist target has shifted in the past few years. The Left is stuck in waging a war it cannot win. What I mean by that is that it is at war with a target (neoliberalism) that no longer exists except in the facades of spectacle and illusion promoted in the vast Industrial-Media-Complex. What is going on in the world is now shifting toward the East and in new visions of technocapitalism of which such initiatives as Smart Cities by both CISCO (see here) and IBM and a conglomerate of other subsidiary firms and networking partners to build new 21st Century infrastructures and architectures to promote creativity, innovation, ultra-modernity, and technocapitalism.
Let’s face it capitalism is once again reinventing itself in a new guise and all the Foundations, Think-Tanks, academic, and media blitz hype artists are slowly pushing toward a different order than the older market economy of neoliberalism. So it’s time the Left begin addressing the new target and its ideological shift rather than attacking the boogeyman of capitalism’s past. Oh, true, the façade of neoliberalism will remain in the EU and U.S.A. and much of the rest of the world for a long while yet, so there is a need to continue our watchdog efforts on that score. But what I’m getting at is that we need to move forward and overtake this new agenda that is slowly creeping into the mix before it suddenly displaces any forms of resistance. So far I’m not sure if this new technocapitalistic ideology has even registered on the major leftist critiques beyond a few individuals like Luis Suarez-Villa. Mark Bergfield has a good critique of Suarez-Villa’s first book on Marx & Philosophy site: here.
In other words, the continuation of capitalist domination is due to its evolution relative to the stagnation of intellectual critiques of it. Or to put it another way, privilege is the capacity to evolve and not merely reproduce. Indeed, the language game of academic criticality is won by those who develop and disseminate new tropes through which to represent the interests of the marginalized. These privileged academics accomplish what Lyotard describes as “legitimation through paralogy.”
* * * * *
If James were working merely within academic criticality, I would be less interested in the work. But her aspirations appear to be higher, in a new political philosophy that can provide normative guidance in a world where data science is a technical reality. She writes:
Mill has already made–in 1859 no less–the argument that rationalizes the sacrifice of individual liberty for social harmony: as long as such harmony is enforced as a matter of opinion rather than a matter of law, then nobody’s violating anybody’s individual rights or liberties. This is, however, a crap argument, one designed to limit the possibly revolutionary effects of actually granting individual liberty as more than a merely formal, procedural thing (emancipating people really, not just politically, to use Marx’s distinction). For example, a careful, critical reading of On Liberty shows that Mill’s argument only works if large groups of people–mainly Asians–don’t get individual liberty in the first place. [2] So, critiquing Mill’s argument may help us show why updated data-science versions of it are crap, too. (And, I don’t think the solution is to shore up individual liberty–cause remember, individual liberty is exclusionary to begin with–but to think of something that’s both better than the old ideas, and more suited to new material/technical realities.)
It’s because of these more universalist ambitions that I think it’s fair to point out the limits of her argument. If a government’s idea of “social harmony” is not in fact white capitalist but premodern Chinese, if “neoliberalism” is no longer the dominant ideology but rather an idea of an ideology reproduced by a stagnating academic discipline, then these ideas will not help us understand what is going on in the contemporary world in which ‘data science’ is allegedly of such importance.
What would be better than this?
There is an empirical reality to the practices of data science. Perhaps it should be studied on its own terms, without disciplinary baggage.
I’m at a difficult crossroads with BigBang where I need to pick an appropriate data storage backend for my preprocessed mailing list data.
There are a lot of different aspects to this problem.
The first and most important consideration is speed. If you know anything about computer science, you know that it exists to quickly execute complex tasks that would take too long to do by hand. It’s odd writing that sentence since computational complexity considerations are so fundamental to algorithm design that this can go unspoken in most technical contexts. But since coming to grad school I’ve found myself writing for a more diverse audience, so…
The problem I’m facing is that in doing exploratory data analysis, I do not know all the questions I am going to ask yet. But any particular question will be impractical to ask unless I tune the underlying infrastructure to answer it. This chicken-and-egg problem means that the process of inquiry is necessarily constrained by the engineering options that are available.
This is not new in scientific practice. Notoriously, the field of economics in the 20th century was shaped by what was analytically tractable as formal, mathematical results. The nuance of contemporary modeling of complex systems is due largely to the fact that we now have computers to do this work for us. That means we can still have the intersubjectively verified rigor that comes with mathematization without trying to fit square pegs into round holes. (Side note: something mathematicians acknowledge that others tend to miss is that mathematics is based on dialectic proof and intersubjective agreement. This makes it much closer epistemologically to something like history as a discipline than it is to technical fields dedicated to prediction and control, like chemistry or structural engineering. Computer science is in many ways an extension of mathematics. Obviously, these formalizations are then applied to great effect. Their power comes from their deep intersubjective validity–in other words, their truth. Disciplines that have dispensed with intersubjective validity as a grounds for truth claims in favor of a more nebulous sense of diverse truths in a manifold of interpretation have difficulty understanding this and so are likely to see the institutional gains of computer scientists to be a result of political manipulation, as opposed to something more basic: mastery of nature, or more provacatively, use of force. This disciplinary disfunction is one reason why these groups see their influence erode.)
For example, I have determined that in order to implement a certain query on the data efficiently, it would be best if another query were constant time. One way to do this is to use a database with an index.
However, setting up a database is something that requires extra work on the part of the programmer and so makes it harder to reproduce results. So far I have been keeping my processed email data “in memory” after it is pulled from files on the file system. This means that I have access to the data within the programming environment I’m most comfortable with, without depending on an external or parallel process. Fewer moving parts means that it is simpler to do my work.
So there is a tradeoff between the computational time of the software as it executes and the time and attention is takes me (and others that want to reproduce my results) to set up the environment in which the software runs. Since I am running this as an open source project and hope others will build on my work, I have every reason to be lazy, in a certain sense. Every inconvenience I suffer is one that will be suffered by everyone that follows me. There is a Kantian categorical imperative to keep things as simple as possible for people, to take any complex procedure and replace it with a script, so that others can do original creative thinking, solve the next problem. This is the imperative that those of us embedded in this culture have internalized. (G. Coleman notes that there are many cultures of hacking; I don’t know how prevalent these norms are, to be honest; I’m speaking from my experience) It is what makes this social process of developing our software infrastructure a social one with a modernist sense of progress. We are part of something that is being built out.
There are also social and political considerations. I am building this project intentionally in a way that is embedded within the Scientific Python ecosystem, as they are also my object of study. Certain projects are trendy right now, and for good reason. At the Python Worker’s Party at Berkeley last Friday, I saw a great presentation of Blaze. Blaze is a project that allows programmers experienced with older idioms of scientific Python programming to transfer their skills to systems that can handle more data, like Spark. This is exciting for the Python community. In such a fast moving field with multiple interoperating ecosystems, there is always the anxiety that ones skills are no longer the best skills to have. Has your expertise been made obsolete? So there is a huge demand for tools that adapt one way of thinking to a new system. As more data has become available, people have engineered new sophisticated processing backends. Often these are not done in Python, which has a reputation for being very usable and accessible but slow to run in operation. Getting the usable programming interface to interoperate with the carefully engineered data backends is hard work, work that Matt Rocklin is doing while being paid by Continuum Analytics. That is sweet.
I’m eager to try out Blaze. But as I think through the questions I am trying to ask about open source projects, I’m realizing that they don’t fit easily into the kind of data processing that Blaze currently supports. Perhaps this is dense on my part. If I knew better what I was asking, I could maybe figure out how to make it fit. But probably, what I’m looking at is data that is not “big”, that does not need the kind of power that these new tools provide. Currently my data fits on my laptop. It even fits in memory! Shouldn’t I build something that works well for what I need it for, and not worry about scaling at this point?
But I’m also trying to think long-term. What happens if an when it does scale up? What if I want to analyze ALL the mailing list data? Is that “big” data?
“Premature optimization is the root of all evil.” – Donald Knuth
There are polarizing discourses on the Internet about the following four dichotomies:
Public vs. Private (information)
(Social) Inclusivity vs. Exclusivity.
Open vs. Closed (systems, properties, communities).
Each of these pairings enlists certain metaphors and intuitions. Rarely are they precisely defined.
Due to their intuitive pull, it’s easy to draw certain naive associations. I certainly do. But how do they work together logically?
To what extent can we fill in other octants of this cube? Or is that way of modeling it too simplistic as well?
If privacy is about having contextual control over information flowing out of oneself, then that means that somebody must have the option of closing off some access to their information. To close off access is necessarily to exclude.
PRIVATE => ¬OPEN => ¬INCLUSIVE
But it has been argued that open sociotechnical systems exclude as well by being inhospitable to those with greater need for privacy.
OPEN => ¬PRIVATE => ¬INCLUSIVE
These conditionals limit the kinds of communities that can exist.
PRIVATE
OPEN
INCLUSIVE
POSSIBLE?
T
T
T
F
T
T
F
F
T
F
T
F
T
F
F
T
F
T
T
F
F
T
F
T
F
F
T
F
F
F
F
T
Social inclusivity in sociotechnical systems is impossible. There is no such thing as a sociotechnical system that works for everybody.
There are only three kinds of systems: open systems, private systems, or systems that are neither open nor private. We can call the latter leaky systems.
These binary logical relations capture only the limiting properties of these systems. If there has ever been an open system, it is the Internet; but everyone knows that even the Internet isn’t truly open because of access issues.
The difference between a private system and a leaky system is participant’s ability to control how their data escapes the system.
But in this case, systems that we call ‘open’ are often private systems, since participants choose whether or not to put information into the open.
So is the only question whether and when information is disclosed vs. leaked?
So I am trying to write a dissertation prospectus. It is going…OK.
The dissertation is on Evaluating Data Science Environments.
But I’ve been getting very distracted by the politics of data science. I have been dealing with the politics by joking about them. But I think I’m in danger of being part of the problem, when I would rather be part of the solution.
So, where do I stand on this, really?
Here are some theses:
There is a sense of “data science” that is importantly different from “data analytics”, though there is plenty of abuse of the term in an industrial context. That claim is awkward because industry can easily say they “own” the term. It would be useful to lay out specifically which computational methods constitute “data science” methods and which don’t.
I think that it’s useful analytically to distinguish different kinds of truth claims because it sheds light on the value of different kinds of inquiry. There is definitely a place for rigorous interpretive inquiry and critical theory in addition to technical, predictive science. I think politicing around these divisions is lame and only talk about it to make fun of the situation.
New computational science techniques have done and will continue to do amazing work in the physical and biological and increasingly environmental sciences. I am jealous of researchers in those fields because I think that work is awesome. For some reason I am a social scientist.
The questions surrounding the application of data science to social systems (which can include environmental systems) are very, very interesting. Qualitative researchers get defensive about their role in “the age of data science” but I think this is unwarranted. I think it’s the quantitative social science researchers who are likely more threatened methodologically. But since I’m not well-trained as a quantitative social scientist really, I can’t be sure of that.
The more I learn about research methods (which seems to be all I study these days, instead of actually doing research–I’m procrastinating), the more I’m getting a nuanced sense of how different methods are designed to address different problems. Jockeying about which method is better is useless. If there is a political battle I think is worth fighting any more, it’s the battle about whether or not transdisciplinary research is productive or possible. I hypothesize that it is. But I think this is an empirical question whose answer may be specific: how can different methods be combined effectively? I think this question gets quite deep and answering it requires getting into epistemology and statistics in a serious way.
What is disruptive about data science is that some people have dug down into statistics in a serious way, come up with a valid general way of analyzing things, and then automated it. That makes it in theory cheaper to pick up and apply than the quantitative techniques used by other researchers, and usable at larger scale. On the whole this is pretty good, though it is bad when people don’t understand how the tools they are using work. Automating science is a pretty good thing over all.
It’s really important for science, as it is automated, to be built on open tools and reproducible data because (a) otherwise there is no reason why it should have the public trust, (b) because it will remove barriers to training new scientists.
All scientists are going to need to know how to program. I’m very fortunate to have a technical background. A technical background is not sufficient to do science well. One can use technical skills to assist in both qualitative (visualization) and quantitative work. The ability to use tools is orthogonal to the ability to study phenomena, despite the historic connection between mathematics and computer science.
People conflate programming, which is increasingly a social and trade skill, with the ability to grasp high level mathematical concepts.
Computers are awesome. The people that make them better deserve the credit they get.
Sometimes I think: should I be in a computer science department? I think I would feel better about my work if I were in CS. I like the feeling of tangible progress and problem solving. I think there are a lot of really important problems to solve, and that the solutions will likely come from computer science related work. What I think I get from being in a more interdisciplinary department is a better understanding of what problems are worth solving. I don’t mean that in a way that diminishes the hard work of problem solving, which I think is really where the rubber hits the road. It is easy to complain. I don’t work as hard as computer science students. I also really like being around women. I think they are great and there aren’t enough of them in computer science departments.
I’m interested in modeling and improving the cooperation around open scientific software because that’s where I see there some real potential value add. I’ve been and engineer and I’ve managed engineers. Managing engineers is a lot harder than engineering, IMO. That’s because management requires navigating a social system. Social systems are really absurdly complicated compared to even individual organisms.
There are three reasons why it might be bad to apply data science to social systems. The first is that it could lead to extraordinarily terrible death robots. My karma is on the line. The second is that the scientific models might be too simplistic and lead to bad decisions that are insensitive to human needs. That is why it is very, very important that the existing wealth of social scientific understanding is not lost but rather translated into a more robust and reproducible form. The third reason is that social science might be in principle impossible due to its self-referential effects. This would make the whole enterprise a collosal waste of time. The first and third reasons frequently depress me. The second motivates me.
Infrastructure and mechanism design are powerful means of social change, perhaps the most powerful. Movements are important but civil society is so paralyzed by the steering media now that it is more valuable to analyze movements as sociotechnical organizations alongside corporations etc. than to view them in isolation from the technical substrate. There are a variety of ideological framings of this position, each with different ideological baggage. I’m less concerned with that, ultimately, than the pragmatic application of knowledge. I wish people would stop having issues with “implications for design.”
I said I wanted to get away from politics, but this is one other political point I actually really think is worth making, though it is generally very unpopular in academia for obvious reasons: the status differential between faculty and staff is an enormous part of the problem of the disfunction of universities. A lot of disciplinery politics are codifications of distaste for certain kinds of labor. In many disciplines, graduate students perform labor unexpertly in service of their lab’s principal investigators; this labor is a way of paying ones dues that has little to do with the intellectual work of their research expertise. Or is it? It’s entirely unclear, especially when what makes the difference between a good researcher and a great one are skills that have nothing to do with their intellectual pursuit, and when master new tools is so essential for success in ones field. But the PIs are often not able to teach these tools. What is the work of research? Who does it? Why do we consider science to be the reserve of a specialized medieval institution, and call it something else when it is done by private industry? Do academics really have a right to complain about the rise of the university administrative class?
Whatever might actually happen as a result of the launch, what was said at the launch was epic.
Vice Chancellor of research Graham Flemming introduced Chancellor Nicholas Dirks for the welcoming remarks. Dirks is UC Berkeley’s 10th Chancellor. He succeeded Robert Birgeneau, who resigned gracefully shortly after coming under heavy criticism for his handling of Occupy Cal, the Berkeley campus’ chapter of the Occupy movement. He was distinctly unsympathetic to the protesters, and there was a widely circulated petition declaring a lack of confidence in his leadership. Birgeneau is a physicist. Dirks is an anthropologist who has championed postcolonial approaches. Within the politics of the university, which are a microcosm of politics at large, this signalling is clear. Dirks’ appointment was meant to satisfy the left wing protesters, most of whom have been trained in softer social sciences themselves. Critical reflection on power dynamics and engagement in activism–which is often associated with leftist politics–are, at least formally, accepted by the university administration as legitimate. Birgeneau would subsequently receive awards for his leadership in drawing more women into the sciences and aiding undocumented students.
Dirks’ welcoming remarks were about the great accomplishments of UC Berkeley as a research institution and the vague but extraordinary potential of BIDS. He is grateful, as we all are, for the funding from the Moore and Sloan foundations. I found his remarks unspecific, and I couldn’t help but wonder what his true thoughts were about data science in the university. Surely he must have an opinion. As an anthropologist, can he consistently believe that data science, especially in the social sciences, is the future?
Vicki Chandler, Chief Program Officer from the Moore Foundation, was more lively. Pulling no punches, she explained that the purpose of BIDS is to shake up scientific culture. Having hung out in Berkeley in the 60’s and attended it as an undergraduate in the 70’s, she believes we are up for it. She spoke again and again of “revolution”. There is ambiguity in this. In my experience, faculty are divided on whether they see the proposed “open science” changes as imminent or hype, as desirable or dangerous. More and more I see faculty acknowledge that we are witnessing the collapse of the ivory tower. It is possible that the BIDS launch is a tipping point. What next? “Let the fun begin!” concluded Chandler.
Saul Perlmutter, Nobel laureate physicist and front man of the BIDS co-PI super group, gave his now practiced and condensed pitch for the new Institute. He hit all the high points, pointing out not only the potential of data science but the importance of changing the institutions themselves. Rethinking the peer-review journal from scratch, he said, we should focus more on code reuse. Software can be a valid research output. As much as open science is popular among the new generation of scientists, this is a bold statement for somebody with such credibility within the university. He even said that the success of open source software is what gives us hope for the revolutionary new kind of science BIDS is beginning. Two years ago, this was a fringe idea. Perlmutter may have just made it mainstream.
Notably, he also engaged with the touchy academic politics, saying that data science could bring diversity to the sciences (though he was unspecific about the mechanism for this). He expounded on the important role of ethnography in evaluating the Institute to identify the bottlenecks to its unlocking its potential.
The man has won at physics and is undoubtedly a scientist par excellance. Perhaps Perlmutter sees the next part of his legacy as the bringing of the university system into the 21st century.
David Culler, Chair of the Electrical Engineering and Computer Science department, then introduced a number of academic scientists, each with impressive demonstrations about how data science could be applied to important problems like climate change and disaster reduction. Much of this research depends on using the proliferation of hand-held mobile devices as sensors. University science, I realized while watching this, is at its best when doing basic research about how to save humanity from nature or ourselves.
But for me the most interesting speakers in the first half of the launch were luminaries Peter Norvig and Tim O’Reilly, each giants in their own right and welcome guests to the university.
Culler introduced Norvig, Director of Research at Google, by crediting him as one of the inventors of the MOOC. I know his name mainly as a co-author of “Artificial Intelligence: A Modern Approach,” which I learned and taught from as an undergraduate. Amazingly, Norvig’s main message is about the economics of the digital economy. Marginal production is cheap, cost of communication is cheap, and this leads to an accumulation of wealth. Fifty percent of jobs are predicted to be automated away in the coming decades. He is worried about the 99%–freely using Occupy rhetoric. What will become of them? Norvig’s solution, perhaps stated tongue in cheek, is that everyone needs to become a data scientist. More concretely, he has high hopes for hybrid teams of people and machines, that all professions will become like this. By defining what academic data science looks like and training the next generation of researchers, BIDS will have a role in steering the balance of power between humanity and the machines–and the elite few who own them.
His remarks hit home. He touched on anxieties that are as old as the Industrial Revolution: is somebody getting immensely rich off of these transformations, but not me? What will my role be in this transformed reality? Will I find work? These are real problems and Norvig was brave to bring them up. The academics in the room were not immune from these anxieties either, as they watch the ivory tower crumble around them. This would come up again later in the day.
I admire him for bringing up the point, and I believe he is sincere. I’d heard him make the same points when he was on a panel with Neil Stephenson and Jaron Lanier a month or so earlier. I can’t help but be critical of Norvig’s remarks. Is he covering his back? Many university professors are seeing MOOCs themselves as threatening to their own careers. It is encouraging that he sees the importance of hybrid human/machine teams. If the machines are built on Google infrastructure, doesn’t this contribute to the same inequality he laments, shifting power away from teachers to the 1% at Google? Or does he foresee a MOOC-based educational boom?
He did not raise the possibility that human/machine hybridity is already the status quo–that, for example, all information workers tap away at these machines and communicate with each other through a vast technical network. If he had acknowledged that we are all cyborgs already, he would have had to admit that hybrid teams of humans and machines are as much the cause of as solution to economic inequality. Indeed, this relationship between human labor and mechanical capital is precisely the same as the one that created economic inequality in the Industrial Revolution. When the capital is privately owned, the systems of hybrid human/machine productivity favor the owner of the machines.
I have high hopes that BIDS will address through its research Norvig’s political concern. It is certainly on the mind of some of its co-PI’s, as later discussion would show. But to address the problem seriously, it will have to look at the problem in a rigorous way that doesn’t shy away from criticism of the status quo.
The next speaker, Tim O’Reilly, is a figure who fascinates me. Culler introduced him as a “God of the Open Source Field,” which is poetically accurate. Before coming to academia, I worked on Web 2.0 open source software platforms for open government. My career was defined by a string of terms invented and popularized by O’Reilly, and to a large extent I’m still a devotee of his ideas. But as a practitioner and researcher, I’ve developed a nuanced view of the field that I’ve tried to convey in the course on Open Collaboration and Peer Production I’ve co-instructed with Thomas Maillart this semeser.
O’Reilly came under criticism earlier this year from Evgeny Morozov, who attacked him for marketing politically unctuous ideas while claiming to be revolutionary. He focuses on his promotion of ‘open source’ over and against Richard Stallman’s explicitly ethical and therefore contentious term ‘free software‘. Morozov accuses O’Reilly of what Tom Scocca has recently defined as rhetorical smarm–dodging specific criticism by denying the appropriateness of criticism in general. O’Reilly has disputed the Morozov piece. Elsewhere he has presented his strategy as a ‘marketer of big ideas‘, and his deliberate promoting of more business-friendly ‘open source’ rhetoric. This ideological debate is itself quite interesting. Geek anthropologist Chris Kelty observes that it is participation in this debate, more so than an adherence to any particular view in it, that characterizes the larger “movement,” which he names the recursive public.
Despite his significance to me, with an open source software background, I was originally surprised when I heard Tim O’Reilly would be speaking at the BIDS launch. O’Reilly had promoted ‘open source’ and ‘Web 2.0’ and ‘open government’, but what did that have to do with ‘data science’?
So I was amused when Norvig introduced O’Reilly by saying that he didn’t know he was a data scientist until the latter wrote an article in Forbes (in November 2011) naming him one of “The World’s 7 Most Powerful Data Scientists.” Looking at the Google Trends data, we can see that November 2011 just about marks the rise of ‘data science’ from obscurity to popularity. Is Tim O’Reilly responsible for the rise of ‘data science’?
Perhaps. O’Reilly’s explained that he got into data science by thinking about the end game for open source. As open source software becomes commodified (which for him I think means something like ‘subject to competitive market pressure), what becomes valuable is the data. And so he has been promoting data science in industry and government, and believes that the university can learn important lessons from those fields as well. He held up his Moto X phone, explained how it is ‘always listening’ and so can facilitate services like Google Now. All this would go towards a system with greater collective intelligence, a self-regulating system that would make regulators obsolete.
Looking at the progression of the use of maps, from paper to digital to being embedded in services and products like self-driving cars, O’Reilly agrees with Norvig about the importance of human-machine interaction. In particular, he believes that data scientists will need to know how to ask the right questions about data, and that this is the future of science. “Others will be left behind,” he said, not intending to sound foreboding.
I thought O’Reilly presented the combination of insight and boosterism I expected. To me, his presence at the BIDS launch meant to me that O’Reilly’s significance as a public intellectual has progressed from business through governance and now to scientific thinking itself. This is wonderful for him but means that his writings and influence should be put under the scrutiny we would have for an academic peer. It is appropriate to call him out for glossing over the privacy issues around a mobile phone that is “always listening,” or the moral implications of the obsolescence of regulators for equality and justice. Is his objectivity compromised by the fact that he runs a publishing company that sells complementary goods to the vast supply of publicly available software and data? Does his business agenda incentivize him to obscure the subtle differences between various segements of his market? Are we in the university victims of that obscurity as we grapple with multiple conflated meanings of “openness” in software and science (open to scrutiny and accountability, vs. open for appropriation by business, vs. open to meritocratic contribution)? As we ask these questions, we can be grateful to O’Reilly for getting us this far.
I’ve emphasized the talks given by Norvig and O’Reilly because they exposed what I think are some of the most interesting aspects of BIDS. One way or another, it will be revolutionary. Its funders will be very disappointed if it is not. But exactly how it is revolutionary is undetermined. The fact that BIDS is based in Berkeley, and not in Google or Microsoft or Stanford, guarantees that the revolution will not be an insipid or smarmy one which brushes aside political conflict or morality. Rather, it promises to be the site of fecund political conflict. “Let the fun begin!” said Chandler.
The opening remarks concluded and we broke for lunch and poster sessions–the Data Science Faire (named after O’Reilly’s Maker Faire…
@sbenthall And that in turn was a reference to the Renaissance Faire. Cultural references get buried like potsherds at ancient Troy.
What followed was a fascinating panel discussion led by astrophysicist Josh Bloom, historian and university administrator Cathryn Carson, computer science professor and AMP Lab director Michael Franklin, and Deb Agrawal, a staff computer scientist for Lawrence Berkeley National Lab.
Bloom introduced the discussion jokingly as “just being among us scientists…and whoever is watching out there on the Internet,” perhaps nodding to the fact that the scientific community is not yet fully conscious that their expectations of privileged communication are being challenged by a world and culture of mobile devices that are “always listening.”
The conversation was about the role of people in data science.
Carson spoke as a domain scientist–a social scientist who studies scientists. Noting that social scientists tend to work in small teams lead by graduate students motivated by their particular questions, she said her emphasis was on the people asking questions. Agrawal noted that the number of people needed to analyze a data set does not scale with the size of data, but the complexity of data–a practical point. (I’d argue that theoretically we might want to consider “size” of data in terms of its compressibility–which would reflect its complexity. This ignores a number of operational challenges.) For Franklin, people are a computational resource that can be part of a crowd-sourced process. In that context, the number of people needed does indeed scale with the use of people as data processors and sensors.
Perhaps to follow through on Norvig’s line of reasoning, Bloom then asked pointedly if machines would ever be able to do the asking of questions better than human beings. In effect: Would data science make data scientists obsolete?
Nobody wanted to be the first to answer this question. Bloom had to repeat it.
Agrawal took a first stab at it. The science does not come from the data; the scientist chooses models and tests them. This is the work of people. Franklin agreed and elaborated–the wrong data too early can ruin the science. Agrawal noted that computers might find spurious signals in the noise.
Personally, I find these unconvincing answers to Bloom’s question. Algorithms can generate, compare, and test alternative models against the evidence. Noise can, with enough data, be filtered away from the signal. To do so pushes the theoretical limits of computing and information theory, but if Franklin is correct in his earlier point that people are part of the computational process, then there is no reason in principle why these tasks too might not be performed if not assisted by computers.
Carson, who had been holding back her answer to listen to the others, had a bolder proposal: rather than try to predict the future of science, why not focus on the task of building that future?
In another universe, at that moment someone might have asked the one question no computer could have answered. “If we are building the new future of science, what should we build? What should it look like? And how do we get there?” But this is the sort of question disciplined scientists are trained not to ask.
Instead, Bloom brought things back to practicality: we need to predict where science will go in order to know how to educate the next generation of scientists. Should we be focusing on teaching them domain knowledge, or on techniques?
We have at the heart of BIDS the very fundamental problem of free will. Bloom suggests that if we can predict the future, then we can train students in anticipation of it. He is an astrophysics and studies stars; he can be forgiven for the assumption that bodies travel in robust orbits. This environment is a more complex one. How we choose to train students now will undoubtedly affect how science evolves, as the process of science is at once the process of learning and training new scientists. His descriptive question then falls back to the normative one: what science are we trying to build toward?
Carson was less heavy-handed than I would have been in her position. Instead, she asked Bloom how he got interested in data science. Bloom recalled his classical physics training, and the moment he discovered that to answer the kinds of questions he was asking, he would need new methods.
Franklin chimed in on the subject of education. He has heard it said that everyone in the next generation should learn to code. With marked humility for his discipline, he said he did not agree with this. But he said he did believe that everyone in the next generation should learn data literacy, echoing Norvig.
Bloom opened the discussion to questions from the audience.
The first was about the career paths for methodologists who write software instead of papers. How would BIDS serve them? It was a soft ball question which the panel hit out of the park. Bloom noted that the Moore and Sloan funders explicitly asked for the development of alternative metrics to measure the impact of methodologist contributions. Carson said that even with the development of metrics, as an administrator she knew it would be a long march through the institution to get those metrics recognized. There was much work to be done. “Universities got to change,” she rallied. “If we don’t change, Berkeley’s being great in the past won’t make it great in the future,” referring perhaps to the impressive history of research recounted by Chancellor Dirks. There was applause. Franklin pointed out that the open source community has its own metrics already. In some circles some of his students are more famous than he is for developing widely used software. Investors are often asking him when his students will graduate. The future, it seems, is bright for methodologists.
At this point I lost my Internet connection and had to stop livetweeting the panel; those tweets are the notes from which I am writing these reflections. Recalling from memory, there was one more question from Kristina Kangas, a PhD student in Integrative Biology. She cited research about how researchers interpreting data wind up reflecting back their own biases. What did this mean for data science?
Bloom gave Carson the last word. It is a social scientific fact, she said, that scientists interpret data in ways that fit their own views. So it’s possible that there is no such thing as “data literacy”. These are open questions that will need to be settled by debate. Indeed, what then is data science after all? Turning to Bloom, she said, “I told you I would be making trouble.”
In anticipation of my dissertation research and in an attempt to start a conversation within the emerging data science community at Berkeley, I’m working on a series of blog posts about reflexive data science. I will update this post with an index of them and related pieces as they are published over time.
Explaining how the stated goals of the Berkeley Institute of Data Science–open source, open science, alt-metrics, and empirical evaluation–imply the possibility of an iterative, scientific approach to incentivizing scientists.
I’m in the PhD program at UC Berkeley’s School of Information. Today, I had to turn in my Preliminary Exam, a 24-hour open book, open note examination on the chosen subject areas of my coursework. I got to pick an exam committee of three faculty members, one for each area of speciality. My committee consisted of: Doug Tygar, examining me on Information System Design; John Chuang, the committee chair, examining me on Information Economics and Policy; and Coye Cheshire, examining me on Social Aspects of Information. Each asked me a question corresponding to their domain; generously, they targeted their questions at my interests.
In keeping with my personal policy of keeping my research open, and because I learned while taking the exam the unvielling of @horse_ebooks and couldn’t resist working it into the exam, and because maybe somebody enrolled in or thinking about applying for our PhD program might find it interesting, I’m posting my examination here (with some webifying of links).
At the time of this posting, I don’t yet know if I have passed.
1. Some e-mail spam detectors use statistical machine learning methods to continuously retrain a classifier based on user input (marking messages as spam or ham). These systems have been criticized for being vulnerable to mistraining by a skilled adversary who sends “tricky spam” that causes the classifier to be poisoned. Exam question: Propose tests that can determine how vulnerable a spam detector is to such manipulation. (Please limit your answer to two pages.)
Tests for classifier poisoning vulnerability in statistical spam filtering systems can consist of simulating particular attacks that would exploit these vulnerabilities. Many of these tests are described in Graham-Cumming, “Does Bayesian Poisoning exist?”, 2006 [pdf.gz], including:
For classifiers trained on a “natural” training data set D and a modified training data set D’ that has been generated to include more common words in messages labeled as spam, compare specificity, sensitivity, or more generally the ROC plots of each for performance. This simulates an attack that aims to increase the false positive rate by making words common to hammy messages be evaluated as spammy.
Same as above, but construct D’ to include many spam messages with unique words. This exploits a tendency in some Bayesian spam filters to measure the spamminess of a word by the percentage of spam messages that contain it. If successful, the attack dilutes the classifier’s sensitivity to spam over a variety of nonsense features, allowing more mundane spam to get through the filter as false negatives.
These two tests depend on increasing the number of spam messages in the data set in a way that strategically biases the classifier. This is the most common form of mistraining attack. Interestingly, these attacks assume that users will correctly label the poisoning messages as spam. So these attacks depend on weaknesses in the filter’s feature model and improper calibration to feature frequency.
A more devious attack of this kind would depend on deceiving the users of the filtering system to mislabel spam as ham or, more dramatically, acknowledge true ham that drives up the hamminess of features normally found in spam.
An example of an attack of this kind (though perhaps not intended as an attack per se) is @Horse_ebooks, a Twitter account that gained popularity while posting randomly chosen bits of prose and, only occasionally, links to purchase low quality self-help ebooks. Allegedly, it was originally a spam bot engaged in a poisoning/evasion attack, but developed a cult following who appreciated its absurdist poetic style. Its success (which only grew after the account was purchased by New York based performance artist Jacob Bakkila in 2011) inspired an imitative style of Twitter activity.
Assuming Twitter is retraining on this data, this behavior could be seen as a kind of poisoning attack, albeit by filter’s users against the system itself. Since it may benefit some Twitter users to have an inflated number of “followers” to project an exaggerated image of their own importance, it’s not clear whether it is in the interests of the users to assist in spam detection, or to sabotage it.
Whatever the interests involved, testing for this kind of vulnerability to this “tricky ham” attack can be conducted in a similar way to the other attacks: by padding the modified data set D’ with additional samples with abnormal statistical properties (e.g noisy words and syntax), this time labeled as ham, and comparing the classifiers along normal performance metrics.
2. Analytical models of cascading behavior in networks, e.g., threshold-based or contagion-based models, are well-suited for analyzing the social dynamics in open collaboration and peer production systems. Discuss.
Cascading behavior models are well-suited to modeling information and innovation diffusion over a network. They are well-suited to analyzing peer production systems to the extent that their dynamics consist of such diffusion over a non-trivial networks. This is the case when production is highly decentralized. Whether we see peer production as centralized or not depends largely on the scale of analysis.
Narrowing in, consider the problem of recruiting new participants to an ongoing collaboration around a particular digital good, such as an open source software product or free encyclopedia. We should expect the usual cascading models to be informative about the awareness and adoption of the good. But in most cases awareness and adoption are only necessary not sufficient conditions for active participation in production. This is because, for example, contribution may involve incurring additional costs and so be subject to different constraints than merely consuming or spreading the word about a digital good.
Though threshold and contagion models could be adapted to capture some of this reluctance through higher thresholds or lower contagion rates, these models fail to closely capture the dynamics of complex collaboration because they represent the cascading behavior as homogeneous. In many open collaborative projects, contributions (and the individual costs of providing them) are specialized. Recruited participants come equipped with their unique backgrounds. (von Krogh, G., Spaeth, S. & Lakhani, K. R. “Community, joining, and specialization in open source software innovation: a case study.” (2003)) So adapting behavior cascade models to this environment would require, at minimum, parameterization of per node capacities for project contribution. The participants in complex collaboration fulfil ecological niches more than they reflect the dynamics of large networked populations.
Furthermore, at the level of a closely collaborative on-line community, network structure is often trivial. Projects may be centralized around a mailing list, source code repository, or public forum that effectively makes the communication network a large clique of all participants. Cascading behavior models will not help with analysis of these cases.
On the other hand, if we zoom out to look at open collaboration as a decentralized process–say, of all open source software developers, or of distributed joke production on Weird Twitter–then network structure becomes important again, and the effects of diffusion may dominate the internal dynamics of innovation itself. Whether or not a software developer chooses to code in Python or Ruby, for example, may well depend on a threshold of the developer’s neighbors in a communication network. These choices allow for contagious adoption of new libraries and code.
We could imagine a distributed innovation system in which every node maintained its own repository of changes, some of which it developed on its own and others it adapted from its neighbors. Maybe the network of human innovators, each drawing from their experiences and skills while developing new ones in the company of others, is like this. This view highlights the emergent social behavior of open innovation, putting the technical architecture (which may affect network structure but could otherwise be considered exogenous) in the background. (See next exam question).
My opinion is that while cascading behavior models may in decentralized conditions capture important aspects of the dynamics of peer production, the basic models will fall short because they don’t consider the interdependence of behaviors. Digital products are often designed for penetration in different networks. For example, the choice of programming language in which to implement ones project influences its potential for early adoption and recruitment. Analytic modeling of these diffusion patterns with cascade models could gain from augmenting the model with representations of technical dependency.
3. Online communities present many challenges for governance and collective behavior, especially in common pool and peer-production contexts. Discuss the relative importance and role of both (1) site architectures and (2) emergent social behaviors in online common pool and/or peer-production contexts. Your answer should draw from more than one real-world example and make specific note of key theoretical perspectives to inform your response. Your response should take approximately 2 pages.
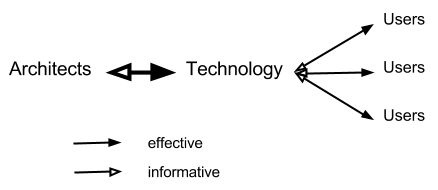
This question requires some unpacking. The sociotechnical systems we are discussing are composed of both technical architecture (often accessed as a web site, i.e. a “location” accessed through HTTP via a web browser) and human agents interacting socially with each other in a way mediated by the architecture (though not exclusively, c.f. Coleman’s work on in person meetings in hacker communities). If technology is “a man-made means to an end” (Heidegger, Question Concerning Technology), then we can ask of the technical architecture: which man, whose end? So questioning the roles of on-line architecture and emergent behaviors brings us to look at how the technology itself was the result of emergent social behavior of its architects. For we can consider “importance” from either the perspective of the users or that of the architects. These perspectives reflect different interests and so will have different standards for evaluating the importance of its components. (c.f. Habermas, Knowledge and Human Interests)
Let us consider socio-technical systems along a spectrum between two extremes. At one extreme are certain prominent systems–e.g. Yelp and Amazon cultivating common pools of reviews–for which the architects and the users are distinct. The site architecture is a means to the ends of the architects, effected through the stimulation of user activity.
Drawing on Winner (“Do artifacts have politics?”), we can see that this socio-technical arrangement establishes a particular pattern of power and authority. Architects have direct control over the technology, which enables to the limits of its affordances user activity. Users can influence architects through the information their activity generates (often collected through the medium of the technical architecture itself), but have no direct coercive control. Rather, architects design the technology to motivate certain desirable activity using inter-user feedback mechanisms such as ways of expressing gratitude or comparing one’s performance with others. (see Cheshire and Antin, “The Social Psychological Effects of Feedback on the Production of Internet Information Pools”, 2008) In such a system, users can only gain control of their technical environment by exploiting vulnerabilities in the architecture in adversarial moves that looks a bit like security breaches. (See the first exam question for an example of user-driven information sabotage.) More likely, the vast majority of users will choose to free ride on any common pool resources made available and exit the system when inconvenienced, as the environment is ultimately a transactional one of service provider and consumer.
In these circumstances, it is only by design that social behaviors lead to peer production and common pools of resources. Technology, as an expression of the interests of the architects, plays a more important role than social emergence. To clarify the point, I’d argue that Facebook, despite hosting enormous amounts of social activity, does not enable significant peer production because its main design goals are to drive the creation of proprietary user data and ad clicks. Twitter, in contrast, has from the beginning been designed as a more open platform. The information shared on it is often less personal, so activity more easily crosses the boundary from private to public, enabling collective action (see Bimber et al., “Reconceptuaizing Collective Action in the Contemporary Media Environment”, 2005) It has facilitated (with varying consistency) the creation of third party clients, as well as applications that interact with its data but can be hosted as separate sites.
This open architecture is necessary but not sufficient for emergent common pool behavior. But the design for open possibilities is significant. It enables the development of novel, intersecting architectures to support the creation of new common pools. Taking Weird Twitter, framed as a peer production community for high quality tweets, as an example, we can see how the service Favstar (which aggregates and ranks tweets that have been highly “starred” and retweeted, and awards congratulatory tweets as prizes) provides historical reminders and relative rankings of tweet quality. Thereby facilitates a culture of production. Once formed, such a culture can spread and make use of other available architecture as well. Weird Twitter has inspired Twitter: The Comic, a Tumblr account illustrating “the greatest tweets of our generation.”
Consider another extreme case, the free software community that Kelty identifies as the recursive public. (Two Bits: The Cultural Significance of Free Software) In an idealized model, we could say that in this socio-technical system the architects and the users are the same.
The artifacts of the recursive public have a different politics than those at the other end of our spectrum, because the coercive aspects of the architectural design are the consequences of the emergent social behavior of those affected by it. Consequently, technology created in this way is rarely restrictive of productive potential, but on the contrary is designed to further empower the collaborative communities that produced it. The history of Unix, Mozilla, Emacs, version control systems, issue tracking software, Wikimedia, and the rest can be read as the historical unfolding of the human interest in an alternative, emancipated form of production. Here, the emergent social behavior claims its importance over and above the particulars of the technology itself.
Though I can barely do justice to the paper, I’ll try to summarize: it grapples with the history of how science became constructed as purely instrumental project (a mode of inquiry that perfects means without specifying particular ends) through the interactions between Heisenberg, the premier theoretical physicist of Germany at his time, and Heidegger, the great philosopher, and then later the response to Heidegger by Habermas.
Heisenberg, most famous perhaps for the Heisenberg Uncertainty Principle, was himself reflective on the role of the scientist within science, and identified the limits of the subject and measurement within physics. But far from surpassing an older metaphysical idea of the subject-object divide, this only entrenched the scientist further, according to Heidegger. This is because scientist qua scientist never encounters the world in a way that is not tied up in the scientific, technical mode and so elludes pure being. While that may simply mean that pure being is left for philosophers and scientists are allowed to go on with their instrumental project, this mode of inquiry becomes insufficient when scientists were called on to comment on nuclear proliferation policy.
Such policy decisions are questions of praxis, or practical action in the human (as opposed to natural) world. Habermas was concerned with the hermeneutic epistemology of praxis, as well as the critical epistemology of emancipation, which are more the purview of the social sciences. Habermas tends to segment these modes of inquiry from each other, without (as far as I’ve encountered so far) anticipating a synthesis.
In data science, we see the broadly positivist, statistical, analytic treatment of social data. In its commercial applications to sell ads or conduct high-speed trading, we could say on a first pass that the science serves the technical human interest: prediction and control for some unspecified end. But that would be misleading. The breadth of methodological options available to the data scientist mean the the methods are often very closely tailored to the particular ends and conditions of the project. Data science as a method is an instrument. But the results of commercial data science are by and large not nomological (identifying laws of human behavior), but rather an immediately applied idiography. Or, more than an applied idiography, data science provides a probabilistic profile of its diverse subjects–an electron cloud of possibilities that the commercial data scientist uses to steer behavior en masse.
Of course, the uncertainty principle applies here as well: the human subject reacts to being measured, has the potential to change direction when they see that they are being targetted with this ad or that.
Further complicating the picture is that the application of ‘social technology’ of commercially driven data science is praxis, albeit in an apolitical sense. Enmeshed in a thick and complex technological web, nevertheless showing an ad and having it be clicked on is a move in the game of social relations. It is a handshake between cyborgs. And so even commercial data science must engage in hermeneutics, if Habermas is correct. Natural language processing provides the uncomfortable edge case here: can we have a technology that accomplishes hermeneutics for us? Apparently so, if a machine can identify somebody’s interest in a product or service from their linguistic output.
Though jarring, this is easier to cope with intellectually if we see the hermeneutic agent as a socio-technical system, as opposed to a purely technical system. Cyborg praxis will includes statistical/technical systems made of wires and silicon, just as meatier praxis includes statistical/technical systems made of proteins and cartilege.
But what of emancipation? This is the least likely human interest to be advanced by commercial interests. If I’ve got my bearings right, the emancipatory interest in the (social) sciences comes from the critical theory tradition, perhaps best exemplified in German thought by the Frankfurt School. One is meant to be emancipated by such inquiry from the power of the capitalist state. What would it mean for there to be an emancipatory data science?
I was recently asked out of the blue in an email whether there were any organizations using machine learning and predictive analytics towards social justice interests. I was ashamed to say I didn’t know of any organizations doing that kind of work. It is hard to imagine what an emancipatory data science would look like. An education or communication about data scientific techniques might be emancipatory (I was trying to accomplish something like this with Why Weird Twitter, for what its worth), but that was a qualitative study, not a data scientific one.
Taking our cue from above, an emancipatory data science would have to use data science methods towards the human interest of emancipation. For this, we would need to use the methods to understand the conditions of power and dependency that bind us. Difficult as an individual, it’s possible that these techniques could be used to greater effect by an emancipatory sociotechnical organization. Such an organization would need to be concerned with its own autonomy as well as the autonomy of others.
The closest thing I can imagine to such a sociotechnical system is what Kelty describes as the recursive public: the loose coallition of open source developers, open access researchers, and others concerned with transforming their social, economic, and technical conditions for emancipatory ends. Happily, the D-Lab’s technical infrastructure team appears to be populated entirely by citizens of the recursive public. Though this is naturally a matter of minor controversy within the lab (its hard to convince folks who haven’t directly experienced the emancipatory potential of the movement of its value), I’m glad that it stands on more or less robust historical grounds. While the course I am co-teaching on Open Collaboration and Peer Production will likely not get into critical theory, I expect that the exposure to more emancipated communities of praxis will make something click.
What I’m going for, personally, is a synthetic science that is at once technical and engaged in emancipatory praxis.