
Towards a Synthesis of Differential Privacy and Contextual Integrity
At last week’s 3rd Annual Symposium on Applications of Contextual Integrity, there was a lively discussion of a top-of-mind concern for computers scientists seeking to work with Contextual Integrity (CI): how does CI relate to differential privacy (DP)? Yan Shvartzshnaider encouraged me to write up my own comments as a blog post.
Differential Privacy (DP)
Differential privacy (Dwork, 2006) is a widely studied paradigm of computational privacy. It is a mathematical property of an algorithm or database 
![Pr[A(D_1) \in S] \leq e^\epsilon \cdot Pr[A(D_2) \in S]](https://s0.wp.com/latex.php?latex=Pr%5BA%28D_1%29+%5Cin+S%5D+%5Cleq+e%5E%5Cepsilon+%5Ccdot+Pr%5BA%28D_2%29+%5Cin+S%5D&bg=fff&fg=444444&s=0&c=20201002)
Where 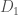

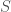
A key motivation for DP is that each individual should, in principle, be indifferent to whether or not they are included in the DP database, because their impact on the result is bounded by a small value, 
There are many, many variations of DP that differ based on assumptions about the generative model of the data set, the privacy threat model, and others ways of relaxing the indifference constraint. However, the technical research of DP is often silent on some key implementation details, such as how to choose the privacy budget
Contextual Integrity (CI)
Contextual Integrity (Nissenbaum, 2009/2020) aims to capture what is socially meaningful about privacy. It defined privacy as appropriate information flow, where appropriateness means alignment with norms based in social context. Following Walzer (2008)’s vision of society divided into separate social spheres, CI recognizes that society is differentiated into many contexts, such as education, healthcare, the workplace, and the family, and that each context has different norms about personal information flow that are adapted to that context’s purpose. For example, the broadly understood rules that doctors keep their patient’s medical information confidential, but can share records with patient’s consent to other medical specialists, are examples of information norms that adhere in the context of healthcare. CI provides a template for understanding information norms, parameterized in terms of:
- Sender of the personal information
- Receiver of the personal information
- Subject of the personal information — the “data subject” in legal terms
- The attribute of the data subject that is referred to or described in the personal information.
- The transmission principle, the normative rule governing the conditions under which the above parameterized information flow is (in)appropriate. Examples of transmission principles include reciprocity, confidentiality, and consent.
Though CI is a theory based in social, philosophical, and legal theories of privacy, it has had uptake in other disciplines, including computer science. These computer science applications have engaged CI deeply and contributed to it by clarifying the terms and limits of the theory (Benthall et al., 2017).
CI has perhaps been best used by computer scientists thus far as a way of conceptualizing the privacy rules of sectoral regulations such as HIPAA, GLBA, and COPPA (Barth et al., 2006) and commercial privacy polices (Shvartzshnaider et al., 2019). However, a promise of CI is that is can address social expectations that have not yet been codified into legal language, helping to bridge between technical design, social expectation, and legal regulation in new and emerging contexts.
Bridging Between DP and CI
I believe it’s safe to say that whereas DP has been widely understood and implemented by computer scientists, it has not sufficed as either a theory or practice to meet the complex and nuanced requirements that socially meaningful privacy entails. On the other hand, while CI does a better job of capturing socially meaningful privacy, it has not yet been computationally operationalized in a way that makes it amenable to widespread implementation. The interest at the Symposium in bridging DP and CI was due to a recognition that CI has defined problems worth solving by privacy oriented computer scientists who would like to build on their deep expertise in DP.
What, then, are the challenges to be addressed by a synthesis of DP and CI? These are just a few conjectures.
Social choice of epsilon. DP is a mathematical theory that leaves open the key question of the choice of privacy budget
Being explicit about context. DP is attractive precisely because it is a property of a mechanism that does not depend on the system’s context (Tschantz et al., 2020). But this is also its weakness. Key assumptions behind the motivation of DP, such as that the data subjects’ qualities are independent from each other, are wrong in many important privacy contexts. Variations of DP have been developed to, for example, adapt to how genetically or socially related people will have similar data, but the choice of which variant to use should be tailored to the conditions of social context. CI can inform DP practice by clarifying which contextual conditions matter and how to map these to DP variations.
DP may only address a subset of CI’s transmission principles. The rather open concept of transmission principle in CI does a lot of work for the theory by making it extensible to almost any conceivable privacy norm. Computer scientists may need to accept that DP will only be able to address a subset of CI’s transmission principles — those related to negative rules of personal information flow. Indeed, some have argued that CI’s transmission principles include rules that will always be incompletely auditable from a computer science perspective. (Datta et al., 2001) DP scholars may need to accept the limits of DP and see CI as a new frontier.
Horizontal data relations and DP for data governance. Increasingly, legal privacy scholars are becoming skeptical that socially meaningful privacy can be guaranteed to individuals alone. Because any individual’s data can enable an inference that has an effect on others, even those who are not in the data set, privacy may not properly be an individual concern. Rather, as Viljoen argues, these horizontal relationships between individuals via their data make personal data a democratic concern properly addressed with a broader understanding of collective or institutional data governance. This democratic data approach is quite consistent with CI, which was among the first privacy theories to emphasize the importance of socially understood norms as opposed to privacy as individual “control” of data. DP can no longer rely on its motivating idea that individual indifference to inclusion in a data set is sufficient for normative, socially meaningful privacy. However, some DP scholars have already begun to expand their expertise and address how DP can play a role in data governance. (Zhang et al., 2020)
DP and CI are two significant lines of privacy research that have not yet been synthesized effectively. That presents an opportunity for researchers in either subfield to reach across the aisle and build new theoretical and computational tools for socially meaningful privacy. In many ways, CI has worked to understand the socially contextual aspects of privacy, preparing the way for more mathematically oriented DP scholars to operationalize them. However, DP scholars may need to relax some of their assumptions and open their minds to make the most of what CI has to offer computational privacy.
References
Barth, A., Datta, A., Mitchell, J. C., & Nissenbaum, H. (2006, May). Privacy and contextual integrity: Framework and applications. In 2006 IEEE symposium on security and privacy (S&P’06) (pp. 15-pp). IEEE.
Benthall, S., Gürses, S., & Nissenbaum, H. (2017). Contextual integrity through the lens of computer science. Now Publishers.
Datta, A., Blocki, J., Christin, N., DeYoung, H., Garg, D., Jia, L., Kaynar, D. and Sinha, A., 2011, December. Understanding and protecting privacy: Formal semantics and principled audit mechanisms. In International Conference on Information Systems Security (pp. 1-27). Springer, Berlin, Heidelberg.
Dwork, C. (2006, July). Differential privacy. In International Colloquium on Automata, Languages, and Programming (pp. 1-12). Springer, Berlin, Heidelberg.
Nissenbaum, H. (2020). Privacy in context. Stanford University Press.
Shvartzshnaider, Y., Pavlinovic, Z., Balashankar, A., Wies, T., Subramanian, L., Nissenbaum, H., & Mittal, P. (2019, May). Vaccine: Using contextual integrity for data leakage detection. In The World Wide Web Conference (pp. 1702-1712).
Shvartzshnaider, Y., Apthorpe, N., Feamster, N., & Nissenbaum, H. (2019, October). Going against the (appropriate) flow: A contextual integrity approach to privacy policy analysis. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing (Vol. 7, No. 1, pp. 162-170).
Tschantz, M. C., Sen, S., & Datta, A. (2020, May). Sok: Differential privacy as a causal property. In 2020 IEEE Symposium on Security and Privacy (SP) (pp. 354-371). IEEE.
Viljoen, S. (forthcoming). Democratic data: A relational theory for data governance. Yale Law Journal.
Walzer, M. (2008). Spheres of justice: A defense of pluralism and equality. Basic books.
Zhang, W., Ohrimenko, O., & Cummings, R. (2020). Attribute Privacy: Framework and Mechanisms. arXiv preprint arXiv:2009.04013.
