There has been a lot of drama on the Internet about AI ethics, and that drama is in the mainstream news. A lot of this drama is about the shakeup in Google’s AI Ethics team. I’ve already written a little about this. I’ve been following the story since, and I would adjust my emphasis slightly. I think the situation is sadder than I did at first. But my take (and I’m sticking to it) is that what’s missing from the dominant narrative in that story, that it is about race and gender representation in tech, (a view quite well articulated in academic argot by Tao and Varshney (2021), by the way) is an analysis of the corporate firm as an organization, what it means to be an employee of a firm, and the relationship between firms and artificial intelligence.
These questions about the corporate firm are not topics that get a lot of traction on the Internet. The topics that get a lot of traction on the Internet are race and gender. I gather that this is something anybody with a blog, (let alone publishing news), discovers. I write this blog for an imagined audience of about ten people. It is mainly research notes to myself. But for some reason, this post about racism got 125 views this past week. For me, that’s a lot of views. Who are those people?
The other dramatic thing going in my corner of the Internet this past week is also about race and gender, and also maybe AI ethics. It is the reaction to Cade Metz’s NYT article “Silicon Valley’s Safe Space“, which is about the blog Slate Star Codex (SSC), rationalist subculture, libertarianism and … racism and sexism.
I learned about this kerfuffle in a backwards way. I learned about it through Glen Weyl’s engagement with SSC about technocracy, which I suppose he was bumping to ride on the shockwave created by the NYT article. In 2019, Weyl posted a critique of “technocracy” which was also a rather pointed attack on the rationalism community, in part because of its connection to “neoreaction”. SSC responded rather adroitly, in my opinion; Weyl responded. It’s an interesting exchange about political theory.
I follow Weyl on Twitter because I disagree with him rather strongly on niche topics in data regulation. As a researcher, I’m all about these niche topics in data regulation; I think they are where the rubber really hits the road on AI ethics. Weyl has published the view that consumer internet data should be treated as a form of labor. In my corner of technology policy research, which is quite small in terms of its Internet footprint, we think this is nonsense; it is what Salome Viljoen calls a propertarian view of data. The propertarian view of data is, for many important reasons, wrong. “Markets are never going to fix the AI/data regulation problem. Go read some Katharina Pistor, for christ’s sake!” That’s the main thing I’ve been waiting to say to Weyl, who has a coveted Microsoft Research position, a successful marketing strategy for his intellectual brand, perfect institutional pedigree, and so on.
Which I mean to his credit: he’s a successful public intellectual. This is why I was surprised to see him tweeting about rationalist subculture, which is not, to me, a legitimate intellectual topic, sanctioned as part of the AI/tech policy/whatever research track. My experiences with rationalism have all been quite personal and para-academic. It is therefore something of a context collapse — the social media induced bridging of social spheres — for me personally. (Marwick and Boyd, 2011; Davis and Jurgenson, 2014)
Context collapse is what it’s all about, isn’t it? One of the controversies around the NYT piece about SSC was that the NYT reporter, Metz, was going to reveal the pseudonymous author of SSC, “Scott Alexander”, as the real person Scott Siskind. This was a “doxxing”, though the connection was easy to make for anybody looking for it. Nevertheless, Siskind initially had a strong personal sense of his own anonymity as a writer. Siskind is, professionally, a psychotherapist, which is a profession with very strong norms around confidentiality and its therapeutic importance. Metz’s article is about this. It is also about race and gender — in particular the ways in which there is a therapeutic need for a space in which to discuss race and gender, as well as other topics, seriously, but also freely, without the major social and professional consequences that have come to be associated with it.
Smart people are writing about this and despite being a “privacy scholar”, I’m not sure I can say much that is smarter. Will Wilkinson’s piece is especially illuminating. His is a defense of journalism and a condemnation of what, I’ve now read, was an angry Internet mob that went after Metz in response to this SSC doxxing. It is also an unpacking of Siskind’s motivations based on his writing, a diagnosis of sorts. Spiers has a related analysis. A theme of these arguments against SSC and the rationalists is, “You weren’t acting so rationally this time, were you?”
I get it. The rationalists are, by presenting themselves at times as smarter-than-thou, asking for this treatment. Certainly in elite intellectual circles, the idea that participation in a web forum should give you advanced powers of reason that are as close as we will ever get to magic is pretty laughable. What I think I can say from personal experience, though, is that elite intellectuals seriously misunderstand popular rationalism if they think that it’s about them. Rather, popular rationalism is a non-elite social movement that’s often for people with non-elite backgrounds and problems. Their “smarter-than-thou” was originally really directed at other non-elite cultural forms, such as Christianity (!). I think this is widely missed.
I say this with some anecdata. I lived in Berkeley for a while in graduate school and was close with some people who were bona fide rationalists. I had an undergraduate background from an Ivy League university in cognitive science and was familiar with the heuristics and biases program and Bayesian reasoning. I had a professional background working in software. I should have fit in, right? So I volunteered twice at the local workshop put on by the Center for Applied Rationality to see what it was all about.
I noticed, as one does, that it’s mostly white men at these workshops and when asked for feedback I pointed this out. Eager to make use of the sociological skills I was learning in grad school, I pointed out that if they did not bring in more diversity early on, then because of homophily effects they may never reach a diverse audience.
At the time, the leadership of CFAR told me something quite interesting. It was that they had looked at their organizational goals and capacities and decided that where they could make the most impact was on teaching the skills of rational thought to smart people from, say, the rural midwest U.S.A. who would otherwise not get the exposure to this kind of thinking or what I would call a community of practice around it. Many of these people (much like Elizabeth Spiers, according to her piece) come from conservative and cloistered Christian backgrounds. Yudkowsky’s Harry Potter and the Methods of Rationality is their first exposure to Bayesian reasoning. They are often the best math students in their homogeneous home town, and finding their way into an engineering job in California is a big deal, as is finding a community that fills an analogous role to organized religion but does not seem so intellectually backwards. I don’t think it’s accidental the Julia Galef, who founded CFAR, started out in intellectual atheist circles before becoming a leader in rationalism. Providing an alternative culture to Christianity is largely what popular rationalism is about.
From this perspective, it makes more sense why Siskind has been able to cultivate a following by discussing cultural issues from a centrist and “altruistic” perspective. There’s a population in the U.S. that grew up in conservative Christian settings, now makes a living in a booming technology sector whose intellectual principles are at odds with those of their upbringing, is trying to “do the right thing” and, being detached from political institutions or power, turns to the question of philanthropy, codified into Effective Altruism. This population is largely comprised of white guys who may truly be upwardly mobile because they are, relative to where they came from, good at math. The world they live in, which revolves around AI, is nothing like the one they grew up in. These same people are regularly confronted by a different ideology, a form of left wing progressivism, which denies their merit, resents their success, and considers them a problem, responsible for the very AI harms that they themselves are committed to solving. If I were one of them, I, too, would want to be part of a therapeutic community where I could speak freely about what was going on.
This is several degrees removed from libertarian politics, which I now see as the line connecting in Weyl. Wilkinson makes the compelling case for contemporary rationalism originating in Tyler Cohen’s libertarian economist blogging and the intellectual environment at George Mason University. This spins out Robin Hanson’s Overcoming Bias blog, which spins out Yudkowsky’s LessWrong forum, which is where popular rationalism incubated. Weyl is an east coast libertarian public intellectual and it makes sense that he would engage other libertarian public intellectuals. I don’t think he’s going to get very far picking fights on the Internet with Yudkowsky, but I could be wrong.
Weyl’s engagement with the rationalist community does highlight for me two other missing elements in the story-as-told-so-far, from my readings on it. I’ve been telling a story partly about geography and migration. I think there’s also an element of shifting centers of cultural dominance. Nothing made me realize that I am a parochial New Yorker like living in California for five years. Rationalism remains weird to me because it is, today, a connection between Oxford utilitarian philosophers, the Silicon Valley nouveau riche, and to some extent Washington, D.C.-based libertarians. That is a wave of culture bypassing the historical intellectual centers of northeast U.S. Ivy League universities which for much of America’s history dominated U.S. politics.
To some extent, this speaks to the significance of the NYT story as well. It was not the first popular article about rationalists; Metz mentions the TechCrunch article about neoreactionaries (I’ll get to that) but not the Sam Frank article in Harpers, “Come With Us If You Want To Live” (2015), which is more ethnographic in its approach. I think it’s a better article. But the NYT has a different audience and a different standard for relevance. NYT is not an intellectual literary magazine. It is the voice of New York City, once the Center of the Universe. New York City’s perspective is particularly weighty, relevant, objective, powerful because of its historic role as a global financial center and marketing center. When the NYT notices something, for a great many people, it becomes real. NYT is at the center of a large public sphere with a specific geographic locus, in a way that some blogs and web forums are not. So whether it was justified or not, Metz’s doxing of Siskind was a significant shift in what information was public, and to whom. Part of its significance is that it was an assertion of cultural power by an institution tied to old money in New York City over a beloved institution of new money in Silicon Valley. In Bourdieusian terms, the article shifted around social and cultural capital in a big way. Siskind was forced to make a trade by an institution more powerful than him. There is a violence to that.
This force of institutional power is perhaps the other missing element in this story. Wilkinson and Frank’s pieces remind me: this is about libertarianism. Weyl’s piece against technocracy is also about libertarianism, or maybe just liberalism. Weyl is arguing that rationalists, as he understands them, are libertarians but not liberals. A “technocrat” is somebody who wants to replace democratic governance mechanisms, which depend on pluralistic discourse, with an expert-designed mechanism. Isn’t this what Silicon Valley does? Build Facebook and act like it’s a nation? Weyl, in my reading, wants an engaged pluralistic public sphere. He is, he reveals later, really arguing with himself, reforming his own views. He was an economist, coming up with mathematical mechanisms to improve social systems through “radical exchange”; now he is a public intellectual who has taken a cultural turn and called AI an “ideology”.
On the other end of the spectrum, there are people that actually would, if they could, build an artificial island and rule it via computers like little lords. I guess Peter Thiel, who plays a somewhat arch-villain role in this story, is like this. Thiel does not like elite higher education and the way it reproduces the ideological conditions for a pluralistic democracy. This is presumably why he backs Curtis Yarvin, the “neoreactionary” writer and “Dark Enlightenment” thinker. Metz goes into detail about this, and traces a connection between Yarvin and SSC; there’s leaked emails about it. To some people, this is the real story. Why? Because neoreaction is racist and sexist. This, not political theory, I promise you, is what is driving the traffic. It’s amazing Metz didn’t use the phrase “red pill” or “alt-right” because that’s definitely the narrative being extended here. With Trump out of office and Amazon shutting down Parler’s cloud computing, we don’t need to worry about the QAnon nutcases (which were, if I’m following correctly, a creation of the Mercers) but what about the right wing elements in the globally powerful tech sector, because… AI ethics! There’s no escape.
Slate Star Codex was a window into the Silicon Valley psyche. There are good reasons to try and understand that psyche, because the decisions made by tech companies and the people who run them eventually affect millions.
And Silicon Valley, a community of iconoclasts, is struggling to decide what’s off limits for all of us.
At Twitter and Facebook, leaders were reluctant to remove words from their platforms — even when those words were untrue or could lead to violence. At some A.I. labs, they release products — including facial recognition systems, digital assistants and chatbots — even while knowing they can be biased against women and people of color, and sometimes spew hateful speech.
Why hold anything back? That was often the answer a Rationalist would arrive at.
Metz’s article has come under a lot of criticism for drawing sweeping thematic links between SSC, neoreaction, and Silicon Valley with very little evidence. Noah Smith’s analysis shows how weak this connection actually is. Silicon Valley is, by the numbers, mostly left-wing, and mostly, by the numbers, not reading rationalist blogs. Thiel, and maybe Musk, are noteworthy exceptions, not the general trend. What does any of this have to do with, say, Zuckerburg? Not much.
The trouble is that if the people in Silicon Valley are left-wing, then there’s nobody to blame for racist and sexist AI. Where could racism and sexism in AI possibly come from, if not some collective “psyche” of the technologists? Better, more progressive leaders in Silicon Valley, the logic goes, would lead to better social outcomes. Pluralistic liberalism and proper demographic representation would, if not for the likes of bad apples like Thiel, steer the AI Labs and the big tech companies that use their products towards equitability and justice.
I want to be clear: I think that affirmative action for under-represented minorities (URMs) in the tech sector is a wonderful thing, and that improving corporate practices around their mentorship, etc. is a cause worth fighting for. I’m not knocking any of that. But I think the idea that this alone will solve the problems of “AI ethics” is a liberal or libertarian fantasy. This is because assuming that the actions of a corporation will have the politics of its employees is a form of ecological fallacy. Corporations do not work for their employees; they work, legally and out of fiduciary duty, to their shareholders. And the AI operated at the grand social scales that we are talking about are not controlled by any one person; they are created and operated corporately.
In my view, what Weyl (who I probably agree with more than I don’t), the earlier libertarian bloggers like Hanson, the AI X-risk folks like Yudkowsky, and the popular rationalist movement all get wrong is the way institutional power necessarily exceeds that of individuals in part because and through of “artificial intelligence”, but also through older institutions that distribute economic and social capital. The “public sphere” is not a flat or radical “marketplace of ideas”; it is an ecology of institutions like the New York Times, playing on ideological receptiveness grounded in religious and economic habitus.
Jeffrey Friedman is a dedicated intellectual and educator, who for years has been a generous intellectual mentor and facilitator of political thought. Friedman, like Weyl, is a critic of technocracy. In an early intellectual encounter that was very formative for me, he invited me to write a book review of Philip Tetlock Expert Political Judgment for his journal. In 2007, it was my first academic publication. The writing is embarrassing and I’m glad it is behind a paywall. In the article, I argue against Friedman and for technocracy based on the use of artificial intelligence. I have been in friendly disagreement on this point with Friedman ever since.
The line of reasoning from Friedman’s book, Power without Knowledge: A Critique of Technocracy (2019), that I find most interesting is about the predictability of individuals. Is it possible for a technocrat to predict society? This question has been posed by many different social theorists. I believe Friedman is unique in suggesting that (a) individuals cannot be predicted by a technocrat because (b) of how individual behavior is determined by their ideas, which are sourced so variously and combined in such complex ways that they cannot be captured by an external or generalizing observer. The unpredictability of society is an objective obstacle to the social scientific prediction that is required for technocratic policies to function effectively and as intended. Instead of a technocracy, Friedman advocates for an “Exitocracy”, based on the idea of Exit from Hirschman, which prioritizes a robust private sector in which citizens can experiment and find happiness, over technocratic or what others might call paternalist public policy. Some of the attractiveness of this model is that it depends on minimal assumptions about the rationality of agents, and especially the agency of technocrats, but still achieves satisficing results. Friedman’s exitocracy is, he argues, a ‘judicious’ technocracy, calibrated to realistic levels of expertise and public ignorance. In allowing for redistribution and centralized governance of some public goods, Friedman’s exitocracy stands as an alternative to more radically libertarian “Exit”-oriented proposals such as those of Srinivasan, which have been associated with Silicon Valley and, by dubious extension, the rationalist community.
At this time, I continue to disagree with Friedman. Academics are particularly unpredictable with respect to their ideas, especially if they do not value prestige or fame as much as their other colleagues. But most people are products of their background, or their habits, or their employers, or their social circles, or their socially structured lived experience. Institutions can predict and control people, largely by offering economic incentives. This predictability is what has made AI effective commercially — in uses by advertisers, for example — and it was what makes centralize public policy, or technocracy, possible.
But I could be wrong about this point. It is an empirical question how and under what conditions people’s beliefs and actions are unpredictable given background conditions. This amount of variability, which we might consider a kind of “freedom”, is a condition for whether technocracy, and AI, is viable or not. Are we free?
References
Davis, J. L., & Jurgenson, N. (2014). Context collapse: Theorizing context collusions and collisions. Information, communication & society, 17(4), 476-485.
Friedman, J. (2019). Power without knowledge: a critique of technocracy. Oxford University Press.
Kollman, K., Miller, J. H., & Page, S. E. (1997). Political institutions and sorting in a Tiebout model. The American Economic Review, 977-992.
Marwick, A. E., & Boyd, D. (2011). I tweet honestly, I tweet passionately: Twitter users, context collapse, and the imagined audience. New media & society, 13(1), 114-133.
Pistor, K. (2020). Rule by data: The end of markets?. Law & Contemp. Probs., 83, 101.
Tao, Y., & Varshney, K. R. (2021). Insiders and Outsiders in Research on Machine Learning and Society. arXiv preprint arXiv:2102.02279.


 which dictates that the output of the mechanism depends only slightly on any one individual data subject’s data. This is most often expressed mathematically as
which dictates that the output of the mechanism depends only slightly on any one individual data subject’s data. This is most often expressed mathematically as![Pr[A(D_1) \in S] \leq e^\epsilon \cdot Pr[A(D_2) \in S]](https://s0.wp.com/latex.php?latex=Pr%5BA%28D_1%29+%5Cin+S%5D+%5Cleq+e%5E%5Cepsilon+%5Ccdot+Pr%5BA%28D_2%29+%5Cin+S%5D&bg=fff&fg=444444&s=0&c=20201002)
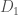 and
and  differ only by the contents on one data point corresponding to a single individual, and
differ only by the contents on one data point corresponding to a single individual, and 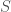 is any arbitrary set of outputs of the mechanism.
is any arbitrary set of outputs of the mechanism. .
.