I’m in the PhD program at UC Berkeley’s School of Information. Today, I had to turn in my Preliminary Exam, a 24-hour open book, open note examination on the chosen subject areas of my coursework. I got to pick an exam committee of three faculty members, one for each area of speciality. My committee consisted of: Doug Tygar, examining me on Information System Design; John Chuang, the committee chair, examining me on Information Economics and Policy; and Coye Cheshire, examining me on Social Aspects of Information. Each asked me a question corresponding to their domain; generously, they targeted their questions at my interests.
In keeping with my personal policy of keeping my research open, and because I learned while taking the exam the unvielling of @horse_ebooks and couldn’t resist working it into the exam, and because maybe somebody enrolled in or thinking about applying for our PhD program might find it interesting, I’m posting my examination here (with some webifying of links).
At the time of this posting, I don’t yet know if I have passed.
1. Some e-mail spam detectors use statistical machine learning methods to continuously retrain a classifier based on user input (marking messages as spam or ham). These systems have been criticized for being vulnerable to mistraining by a skilled adversary who sends “tricky spam” that causes the classifier to be poisoned. Exam question: Propose tests that can determine how vulnerable a spam detector is to such manipulation. (Please limit your answer to two pages.)
Tests for classifier poisoning vulnerability in statistical spam filtering systems can consist of simulating particular attacks that would exploit these vulnerabilities. Many of these tests are described in Graham-Cumming, “Does Bayesian Poisoning exist?”, 2006 [pdf.gz], including:
- For classifiers trained on a “natural” training data set D and a modified training data set D’ that has been generated to include more common words in messages labeled as spam, compare specificity, sensitivity, or more generally the ROC plots of each for performance. This simulates an attack that aims to increase the false positive rate by making words common to hammy messages be evaluated as spammy.
- Same as above, but construct D’ to include many spam messages with unique words. This exploits a tendency in some Bayesian spam filters to measure the spamminess of a word by the percentage of spam messages that contain it. If successful, the attack dilutes the classifier’s sensitivity to spam over a variety of nonsense features, allowing more mundane spam to get through the filter as false negatives.
These two tests depend on increasing the number of spam messages in the data set in a way that strategically biases the classifier. This is the most common form of mistraining attack. Interestingly, these attacks assume that users will correctly label the poisoning messages as spam. So these attacks depend on weaknesses in the filter’s feature model and improper calibration to feature frequency.
A more devious attack of this kind would depend on deceiving the users of the filtering system to mislabel spam as ham or, more dramatically, acknowledge true ham that drives up the hamminess of features normally found in spam.
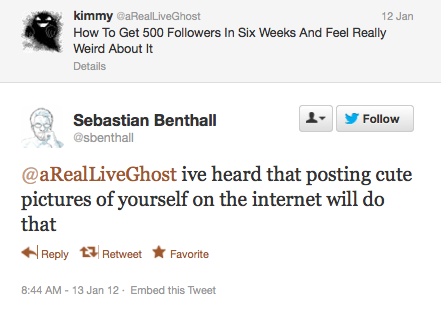
An example of an attack of this kind (though perhaps not intended as an attack per se) is @Horse_ebooks, a Twitter account that gained popularity while posting randomly chosen bits of prose and, only occasionally, links to purchase low quality self-help ebooks. Allegedly, it was originally a spam bot engaged in a poisoning/evasion attack, but developed a cult following who appreciated its absurdist poetic style. Its success (which only grew after the account was purchased by New York based performance artist Jacob Bakkila in 2011) inspired an imitative style of Twitter activity.
Assuming Twitter is retraining on this data, this behavior could be seen as a kind of poisoning attack, albeit by filter’s users against the system itself. Since it may benefit some Twitter users to have an inflated number of “followers” to project an exaggerated image of their own importance, it’s not clear whether it is in the interests of the users to assist in spam detection, or to sabotage it.
Whatever the interests involved, testing for this kind of vulnerability to this “tricky ham” attack can be conducted in a similar way to the other attacks: by padding the modified data set D’ with additional samples with abnormal statistical properties (e.g noisy words and syntax), this time labeled as ham, and comparing the classifiers along normal performance metrics.
2. Analytical models of cascading behavior in networks, e.g., threshold-based or contagion-based models, are well-suited for analyzing the social dynamics in open collaboration and peer production systems. Discuss.
Cascading behavior models are well-suited to modeling information and innovation diffusion over a network. They are well-suited to analyzing peer production systems to the extent that their dynamics consist of such diffusion over a non-trivial networks. This is the case when production is highly decentralized. Whether we see peer production as centralized or not depends largely on the scale of analysis.
Narrowing in, consider the problem of recruiting new participants to an ongoing collaboration around a particular digital good, such as an open source software product or free encyclopedia. We should expect the usual cascading models to be informative about the awareness and adoption of the good. But in most cases awareness and adoption are only necessary not sufficient conditions for active participation in production. This is because, for example, contribution may involve incurring additional costs and so be subject to different constraints than merely consuming or spreading the word about a digital good.
Though threshold and contagion models could be adapted to capture some of this reluctance through higher thresholds or lower contagion rates, these models fail to closely capture the dynamics of complex collaboration because they represent the cascading behavior as homogeneous. In many open collaborative projects, contributions (and the individual costs of providing them) are specialized. Recruited participants come equipped with their unique backgrounds. (von Krogh, G., Spaeth, S. & Lakhani, K. R. “Community, joining, and specialization in open source software innovation: a case study.” (2003)) So adapting behavior cascade models to this environment would require, at minimum, parameterization of per node capacities for project contribution. The participants in complex collaboration fulfil ecological niches more than they reflect the dynamics of large networked populations.
Furthermore, at the level of a closely collaborative on-line community, network structure is often trivial. Projects may be centralized around a mailing list, source code repository, or public forum that effectively makes the communication network a large clique of all participants. Cascading behavior models will not help with analysis of these cases.
On the other hand, if we zoom out to look at open collaboration as a decentralized process–say, of all open source software developers, or of distributed joke production on Weird Twitter–then network structure becomes important again, and the effects of diffusion may dominate the internal dynamics of innovation itself. Whether or not a software developer chooses to code in Python or Ruby, for example, may well depend on a threshold of the developer’s neighbors in a communication network. These choices allow for contagious adoption of new libraries and code.
We could imagine a distributed innovation system in which every node maintained its own repository of changes, some of which it developed on its own and others it adapted from its neighbors. Maybe the network of human innovators, each drawing from their experiences and skills while developing new ones in the company of others, is like this. This view highlights the emergent social behavior of open innovation, putting the technical architecture (which may affect network structure but could otherwise be considered exogenous) in the background. (See next exam question).
My opinion is that while cascading behavior models may in decentralized conditions capture important aspects of the dynamics of peer production, the basic models will fall short because they don’t consider the interdependence of behaviors. Digital products are often designed for penetration in different networks. For example, the choice of programming language in which to implement ones project influences its potential for early adoption and recruitment. Analytic modeling of these diffusion patterns with cascade models could gain from augmenting the model with representations of technical dependency.
3. Online communities present many challenges for governance and collective behavior, especially in common pool and peer-production contexts. Discuss the relative importance and role of both (1) site architectures and (2) emergent social behaviors in online common pool and/or peer-production contexts. Your answer should draw from more than one real-world example and make specific note of key theoretical perspectives to inform your response. Your response should take approximately 2 pages.
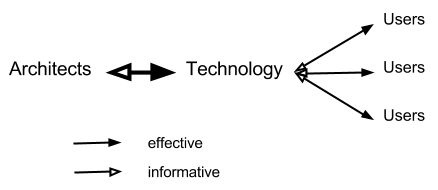
This question requires some unpacking. The sociotechnical systems we are discussing are composed of both technical architecture (often accessed as a web site, i.e. a “location” accessed through HTTP via a web browser) and human agents interacting socially with each other in a way mediated by the architecture (though not exclusively, c.f. Coleman’s work on in person meetings in hacker communities). If technology is “a man-made means to an end” (Heidegger, Question Concerning Technology), then we can ask of the technical architecture: which man, whose end? So questioning the roles of on-line architecture and emergent behaviors brings us to look at how the technology itself was the result of emergent social behavior of its architects. For we can consider “importance” from either the perspective of the users or that of the architects. These perspectives reflect different interests and so will have different standards for evaluating the importance of its components. (c.f. Habermas, Knowledge and Human Interests)
Let us consider socio-technical systems along a spectrum between two extremes. At one extreme are certain prominent systems–e.g. Yelp and Amazon cultivating common pools of reviews–for which the architects and the users are distinct. The site architecture is a means to the ends of the architects, effected through the stimulation of user activity.

Drawing on Winner (“Do artifacts have politics?”), we can see that this socio-technical arrangement establishes a particular pattern of power and authority. Architects have direct control over the technology, which enables to the limits of its affordances user activity. Users can influence architects through the information their activity generates (often collected through the medium of the technical architecture itself), but have no direct coercive control. Rather, architects design the technology to motivate certain desirable activity using inter-user feedback mechanisms such as ways of expressing gratitude or comparing one’s performance with others. (see Cheshire and Antin, “The Social Psychological Effects of Feedback on the Production of Internet Information Pools”, 2008) In such a system, users can only gain control of their technical environment by exploiting vulnerabilities in the architecture in adversarial moves that looks a bit like security breaches. (See the first exam question for an example of user-driven information sabotage.) More likely, the vast majority of users will choose to free ride on any common pool resources made available and exit the system when inconvenienced, as the environment is ultimately a transactional one of service provider and consumer.
In these circumstances, it is only by design that social behaviors lead to peer production and common pools of resources. Technology, as an expression of the interests of the architects, plays a more important role than social emergence. To clarify the point, I’d argue that Facebook, despite hosting enormous amounts of social activity, does not enable significant peer production because its main design goals are to drive the creation of proprietary user data and ad clicks. Twitter, in contrast, has from the beginning been designed as a more open platform. The information shared on it is often less personal, so activity more easily crosses the boundary from private to public, enabling collective action (see Bimber et al., “Reconceptuaizing Collective Action in the Contemporary Media Environment”, 2005) It has facilitated (with varying consistency) the creation of third party clients, as well as applications that interact with its data but can be hosted as separate sites.
This open architecture is necessary but not sufficient for emergent common pool behavior. But the design for open possibilities is significant. It enables the development of novel, intersecting architectures to support the creation of new common pools. Taking Weird Twitter, framed as a peer production community for high quality tweets, as an example, we can see how the service Favstar (which aggregates and ranks tweets that have been highly “starred” and retweeted, and awards congratulatory tweets as prizes) provides historical reminders and relative rankings of tweet quality. Thereby facilitates a culture of production. Once formed, such a culture can spread and make use of other available architecture as well. Weird Twitter has inspired Twitter: The Comic, a Tumblr account illustrating “the greatest tweets of our generation.”
Consider another extreme case, the free software community that Kelty identifies as the recursive public. (Two Bits: The Cultural Significance of Free Software) In an idealized model, we could say that in this socio-technical system the architects and the users are the same.

The artifacts of the recursive public have a different politics than those at the other end of our spectrum, because the coercive aspects of the architectural design are the consequences of the emergent social behavior of those affected by it. Consequently, technology created in this way is rarely restrictive of productive potential, but on the contrary is designed to further empower the collaborative communities that produced it. The history of Unix, Mozilla, Emacs, version control systems, issue tracking software, Wikimedia, and the rest can be read as the historical unfolding of the human interest in an alternative, emancipated form of production. Here, the emergent social behavior claims its importance over and above the particulars of the technology itself.