
Formalizing welfare implications of price discrimination based on personal information
In my last post I formalized Richard Posner’s 1981 argument concerning the economics of privacy. This is just one case of the economics of privacy. A more thorough analysis of the economics of privacy would consider the impact of personal information flow in more aspects of the economy. So let’s try another one.
One major theme of Shapiro and Varian’s Information Rules (1999) is the importance of price differentiation when selling information goods and how the Internet makes price differentiation easier than ever. Price differentiation likely motivates much of the data collection on the Internet, though it’s a practice that long predates the Internet. Shapiro and Varian point out that the “special offers” one gets from magazines for an extension to a subscription may well offer a personalized price based on demographic information. What’s more, this personalized price may well be an experiment, testing for the willingness of people like you to pay that price. (See Acquisti and Varian, 2005 for a detailed analysis of the economics of conditioning prices on purchase history.)
The point of this post is to analyze how a firm’s ability to differentiate its prices is a function of the knowledge it has about its customers and hence outcomes change with the flow of personal information. This makes personalized price differentiation a sub-problem of the economics of privacy.
To see this, let’s assume there are a number of customers for a job, 

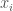
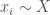
Note two things about how we are setting up this model. The first is that it closely mirrors our formulation of Posner’s argument about hiring job applicants. Whereas before the uncertain personal variable was aptitude for a job, in this case it is willingness to pay.
The second thing to note is that whereas it is typical to analyze price differentiation according to a model of supply and demand, here we are modeling the distribution of demand as a random variable. This is because we are interested in modeling information flow in a specific statistical sense. What we will find is that many of the more static economic tools translate well into a probabilistic domain, with some twists.
Now suppose the firm knows 


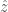
![\hat z = arg \max_z E[\sum_i z [x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+E%5B%5Csum_i+z+%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
![\hat z = arg \max_z \sum_i E[z [x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+%5Csum_i+E%5Bz+%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
![\hat z = arg \max_z \sum_i z E[[x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+%5Csum_i+z+E%5B%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
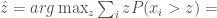

Where ![[x_i > z]](https://s0.wp.com/latex.php?latex=%5Bx_i+%3E+z%5D+&bg=fff&fg=444444&s=0&c=20201002)
This is almost identical to the revenue-optimizing strategy of price selection more generally, and it has a number of similar properties. One property is that for every customer for whom 
Now consider the opposite extreme, wherein the producer knows the willingness to pay of each customer 


What are the welfare implications of the lack of consumer privacy?
Like in the case of Posner’s employer, the real winner here is the firm, who is able to capture all the value added to the market by the increased flow of information. In both cases we have assumed the firm is a monopoly, which may have something to do with this result.
As for consumers, there are two classes of impact. For those with 
For those consumers with 
Unlike in Posner's case, "the people" here are more equal when their personal information is revealed to the firm because now the firm is extracting every spare ounce of joy it can from each of them, whereas before some consumers were able to enjoy low prices relative to their idiosyncratically high appreciation for the good.
What if the firm has access to partial information about each consumer 

![z_i = arg \max_z E[z [P(x_i > z \vert y_i)]]](https://s0.wp.com/latex.php?latex=z_i+%3D+arg+%5Cmax_z+E%5Bz+%5BP%28x_i+%3E+z+%5Cvert+y_i%29%5D%5D&bg=fff&fg=444444&s=0&c=20201002)
The specifics of the distributions 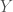

Perhaps the more interesting consequence of this analysis is that the firm has, for each consumer, a subjective probabilistic distribution of that consumer’s demand. Their best strategy for choosing the personalized price is similar to that of choosing a price for a large uncertain consumer demand base, only now the uncertainty is personalized. This probabilistic version of classic price differentiation theory may be more amenable to Bayesian methods, data science, etc.
References
Acquisti, A., & Varian, H. R. (2005). Conditioning prices on purchase history. Marketing Science, 24(3), 367-381.
Shapiro, C., & Varian, H. R. (1998). Information rules: a strategic guide to the network economy. Harvard Business Press.
