
Formalizing Posner’s economics of privacy argument
by Sebastian Benthall
I’d like to take a more formal look at Posner’s economics of privacy argument, in light of other principles in economics of information, such as those in Shapiro and Varian’s Information Rules.
By “formal”, what I mean is that I want to look at the mathematical form of the argument. This is intended to strip out some of the semantics of the problem, which in the case of economics of privacy can lead to a lot of distracting anxieties, often for legitimate ethical reasons. However, there are logical realities that one must face despite the ethical conundrums they cause. Indeed, if there weren’t logical constraints on what is possible, then ethics would be unnecessary. So, let’s approach the blackboard, shall we?
In our interpretation of Posner’s argument, there are a number of applicants for a job, 

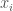
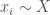
There is an employer who must select an applicant for the job. Let’s assume that their capacity to pay for the job is fixed, for simplicity, and that all applicants are willing to accept the wage. The employer must pick an applicant 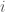

![E[X]](https://s0.wp.com/latex.php?latex=E%5BX%5D&bg=fff&fg=444444&s=0&c=20201002)
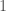
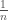
Now suppose the other extreme: the employer has perfect knowledge of the abilities of the applicants. Since she is able to pick the best candidate, her utility is 

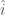
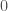
Some things are worth noting about this outcome. There is more inequality. All expected utility from the less qualified applicants has moved to the most qualified applicant. There is also an expected surplus of ![(\max x_i) - E[X]](https://s0.wp.com/latex.php?latex=%28%5Cmax+x_i%29+-+E%5BX%5D&bg=fff&fg=444444&s=0&c=20201002)
![\frac{(\max x_i) - E[X]}{n-1}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%28%5Cmax+x_i%29+-+E%5BX%5D%7D%7Bn-1%7D&bg=fff&fg=444444&s=0&c=20201002)
What about intermediary conditions? These get more analytically complex. Suppose that each applicant 
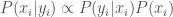
because naturally the employer is a Bayesian reasoner. She makes her decision by maximizing her expected gain, based on this evidence:
![arg\max E[P(x_i \vert y_i)] =](https://s0.wp.com/latex.php?latex=arg%5Cmax+E%5BP%28x_i+%5Cvert+y_i%29%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)


The particulars of the distributions 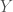

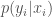
What this goes to show is how ones evaluation of Posner's argument about the economics of privacy really has little to do with the way one feels about privacy and much more to do with how one feels about the equality and economic surplus. I've heard that a similar result has been discovered by Solon Barocas, though I'm not sure where in his large body of work to find it.
