
General intelligence, social privilege, and causal inference from factor analysis
I came upon this excellent essay by Cosma Shalizi about how factor analysis has been spuriously used to support the scientific theory of General Intelligence (i.e., IQ). Shalizi, if you don’t know, is one of the best statisticians around. He writes really well and isn’t afraid to point out major blunders in things. He’s one of my favorite academics, and I don’t think I’m alone in this assessment.
First, a motive: Shalizi writes this essay because he thinks the scientific theory of General Intelligence, or a g factor that is some real property of the mind, is wrong. This theory is famous because (a) a lot of people DO believe in IQ as a real feature of the mind, and (b) a significant percentage of these people believe that IQ is hereditary and correlated with race, and (c) the ideas in (b) are used to justify pernicious and unjust social policy. Shalizi, being a principled statistician, appears to take scientific objection to (a) independently of his objection to (c), and argues persuasively that we can reject (a). How?
Shalizi’s point is that the general intelligence factor g is a latent variable that was supposedly discovered using a factor analysis of several different intelligence tests that were supposed to be independent of each other. You can take the data from these data sets and do a dimensionality reduction (that’s what factor analysis is) and get something that looks like a single factor, just as you can take a set of cars and do a dimensionality reduction and get something that looks like a single factor, “size”. The problem is that “intelligence”, just like “size”, can also be a combination of many other factors that are only indirectly associated with each other (height, length, mass, mass of specific components independent of each other, etc.). Once you have many different independent factors combining into one single reduced “dimension” of analysis, you no longer have a coherent causal story of how your general latent variable caused the phenomenon. You have, effectively, correlation without demonstrated causation and, moreover, the correlation is a construct of your data analysis method, and so isn’t really even telling you what correlations normally tell you.
To put it another way: the fact that some people seem to be generally smarter than other people can be due to thousands of independent factors that happen to combine when people apply themselves to different kinds of tasks. If some people were NOT seeming generally smarter than others, that would allow you to reject the hypothesis that there was general intelligence. But the mere presence of the aggregate phenomenon does not prove the existence of a real latent variable. In fact, Shalizi goes on to say, when you do the right kinds of tests to see if there really is a latent factor of ‘general intelligence’, you find that there isn’t any. And so it’s just the persistent and possibly motivated interpretation of the observational data that allows the stubborn myth of general intelligence to continue.
Are you following so far? If you are, it’s likely because you were already skeptical of IQ and its racial correlates to begin with. Now I’m going to switch it up though…
It is fairly common for educated people in the United States (for example) to talk about “privilege” of social groups. White privilege, male privilege–don’t tell me you haven’t at least heard of this stuff before; it is literally everywhere on the center-left news. Privilege here is considered to be a general factor that adheres in certain social groups. It is reinforced by all manner of social conditioning, especially through implicit bias in individual decision-making. This bias is so powerful it extends not to just cases of direct discrimination but also in cases where discrimination happens in a mediated way, for example through technical design. The evidence for these kinds of social privileging effects is obvious: we see inequality everywhere, and we can who is more powerful and benefited by the status quo and who isn’t.
You see where this is going now. I have the momentum. I can’t stop. Here it goes: Maybe this whole story about social privilege is as spuriously supported as the story about general intelligence? What if both narratives were over-interpretations of data that serve a political purpose, but which are not in fact based on sound causal inference techniques?
How could this be? Well, we might gather a lot of data about people: wealth, status, neighborhood, lifespan, etc. And then we could run a dimensionality reduction/factor analysis and get a significant factor that we could name “privilege” or “power”. Potentially that’s a single, real, latent variable. But also potentially it’s hundreds of independent factors spuriously combined into one. It would probably, if I had to bet on it, wind up looking a lot like the factor for “general intelligence”, which plays into the whole controversy about whether and how privilege and intelligence get confused. You must have heard the debates about, say, representation in the technical (or other high-status, high-paying) work force? One side says the smart people get hired; the other side say it’s the privileged (white male) people that get hired. Some jerk suggests that maybe the white males are smarter, and he gets fired. It’s a mess.
I’m offering you a pill right now. It’s not the red pill. It’s not the blue pill. It’s some other colored pill. Green?
There is no such thing as either general intelligence or group based social privilege. Each of these are the results of sloppy data compression over thousands of factors with a loose and subtle correlational structure. The reason why patterns of social behavior that we see are so robust against interventions is that each intervention can work against only one or two of these thousands of factors at a time. Discovering the real causal structure here is hard partly because the effect sizes are very small. Anybody with a simple explanation, especially a politically convenient explanation, is lying to you but also probably lying to themselves. We live in a complex world that resists our understanding and our actions to change it, though it can be better understood and changed through sound statistics. Most people aren’t bothering to do this, and that’s why the world is so dumb right now.
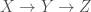 , then
, then  , where here
, where here 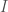 stands for mutual information. Mutual information is a measure of how much two random variables carry information about each other. If $I(X,Y) = 0$, that means the variables are independent. $I(X,Y) \geq 0$ always–that’s just a mathematical fact about how it’s defined.
stands for mutual information. Mutual information is a measure of how much two random variables carry information about each other. If $I(X,Y) = 0$, that means the variables are independent. $I(X,Y) \geq 0$ always–that’s just a mathematical fact about how it’s defined.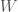 and there’s am organism, or a person, or a sociotechnical organization within it,
and there’s am organism, or a person, or a sociotechnical organization within it, 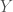 . The world is big and complex, which implies that it has a lot of informational entropy,
. The world is big and complex, which implies that it has a lot of informational entropy, 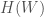 . Through whatever sensory apparatus is available to
. Through whatever sensory apparatus is available to  . This in turn bounds the mutual information between the organism and the world:
. This in turn bounds the mutual information between the organism and the world: 
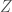 depend only on its internal state. It is an agent, reacting to its environment. Well whatever these actions are, they can only be so calibrated to the world as the agent had capacity to absorb the world’s information. I.e.,
depend only on its internal state. It is an agent, reacting to its environment. Well whatever these actions are, they can only be so calibrated to the world as the agent had capacity to absorb the world’s information. I.e.,  . The implication is that the more limited the mental capacity of the organism, the more its actions will be approximately independent of the state of the world that precedes it.
. The implication is that the more limited the mental capacity of the organism, the more its actions will be approximately independent of the state of the world that precedes it. 