I’m been stimulated by Luciano Floridi’s recent article in Aeon “Should we be afraid of AI?”. I’m surprised that this issue hasn’t been settled yet, since it seems like “we” have the formal tools necessary to solve the problem decisively. But nevertheless this appears to be the subject of debate.
I was referred to Kaj Sotala’s rebuttal of an earlier work by Floridi which his Aeon article was based on. The rebuttal appears in this APA Newsletter on Philosophy and Computers. It is worth reading.
The issue that I’m most interested in is whether or not AI risk research should constitute a special, independent branch of research, or whether it can be approached just as well by pursuing a number of other more mainstream artificial intelligence research agendas. My primary engagement with these debates has so far been an analysis of Nick Bostrom’s argument in his book Superintelligence, which tries to argue in particular that there is an existential risk (or X-risk) to humanity from artificial intelligence. “Existential risk” means a risk to the existence of something, in this case humanity. And the risk Bostrom has written about is the risk of eponymous superintelligence: an artificial intelligence that gets smart enough to improve its own intelligence, achieve omnipotence, and end the world as we know it.
I’ve posted my rebuttal to this argument on arXiv. The one-sentence summary of the argument is: algorithms can’t just modify themselves into omnipotence because they will hit performance bounds due to data and hardware.
A number of friends have pointed out to me that this is not a decisive argument. They say: don’t you just need the AI to advance fast enough and far enough to be an existential threat?
There are a number of reasons why I don’t believe this is likely. In fact, I believe that it is provably vanishingly unlikely. This is not to say that I have a proof, per se. I suppose it’s incumbent on me to work it out and see if the proof is really there.
So: Herewith is my Sketch Of A Proof of why there’s no significant artificial intelligence existential risk.
Lemma: Intelligence advances due to purely algorithmic self-modificiation will always plateau due to data and hardware constraints, which advance more slowly.
Proof: This paper.

As a consequence, all artificial intelligence explosions will be sigmoid. That is, starting slow, accelerating, then decelerating, the growing so slowly as to be asymptotic. Let’s call the level of intelligence at which an explosion asymptotes the explosion bound.
There’s empirical support for this claim. Basically, we have never had a really big intelligence explosion due to algorithmic improvement alone. Looking at the impressive results of the last seventy years, most of the impressiveness can be attributed to advances in hardware and data collection. Notoriously, Deep Learning is largely just decades old artificial neural network technology repurposed to GPU’s on the cloud. Which is awesome and a little scary. But it’s not an algorithmic intelligence explosion. It’s a consolidation of material computing power and sensor technology by organizations. The algorithmic advances fill those material shoes really quickly, it’s true. This is precisely the point: it’s not the algorithms that’s the bottleneck.
Observation: Intelligence explosions are happening all the time. Most of them are small.
Once we accept the idea that intelligence explosions are all bounded, it becomes rather arbitrary where we draw the line between an intelligence explosion and some lesser algorithmic intelligence advance. There is a real sense in which any significant intelligence advance is a sigmoid expansion in intelligence. This would include run-of-the-mill scientific discoveries and good ideas.
If intelligence explosions are anything like virtually every other interesting empirical phenomenon, then they are distributed according to a heavy tail distribution. This means a distribution with a lot of very small values and a diminishing probability of higher values that nevertheless assigns some probability to very high values. Assuming intelligence is something that can be quantified and observed empirically (a huge ‘if’ taken for granted in this discussion), we can (theoretically) take a good hard look at the ways intelligence has advanced. Look around you. Do you see people and computers getting smarter all the time, sometimes in leaps and bounds but most of the time minutely? That’s a confirmation of this hypothesis!

The big idea here is really just to assert that there is a probability distribution over intelligence explosion bounds that all actual intelligence explosions are being drawn from. This follows more or less directly from the conclusion that all intelligence explosions are bounded. Once we posit such a distribution, it becomes possible to take expected values of functions of its values and functions of its values.
Empirical claim: Hardware and sensing advances diffuse rapidly relative to their contribution to intelligence gains.
There’s an material, socio-technical analog to Bostrom’s explosive superintelligence. We could imagine a corporation that is working in secret on new computing infrastructure. Whenever it has an advance in computing infrastructure, the AI people (or increasingly, the AI-writing-AI) develops programming that maximizes its use of this new technology. Then it uses that technology to enrich its own computer-improving facilities. When it needs more…minerals…or whatever it needs to further its research efforts, it finds a way to get them. It proceeds to take over the world.
This may presently be happening. But evidence suggests that this isn’t how the technology economy really works. No doubt Amazon (for example) is using Amazon Web Services internally to do its business analytics. But also it makes its business out of selling out its computing infrastructure to other organizations as a commodity. That’s actually the best way it can enrich itself.
What’s happening here is the diffusion of innovation, which is a well-studied phenomenon in economics and other fields. Ideas spread. Technological designs spread. I’d go so far as to say that it is often (perhaps always?) the best strategy for some agent that has locally discovered a way to advance its own intelligence to figure out how to trade that intelligence to other agents. Almost always that trade involves the diffusion of the basis of that intelligence itself.
Why? Because since there are independent intelligence advances of varying sizes happening all the time, there’s actually a very competitive market for innovation that quickly devalues any particular gain. A discovery, if hoarded, will likely be discovered by somebody else. The race to get credit for any technological advance at all motivates diffusion and disclosure.
The result is that the distribution of innovation, rather than concentrating into very tall spikes, is constantly flattening and fattening itself. That’s important because…
Claim: Intelligence risk is not due to absolute levels of intelligence, but relative intelligence advantage.
The idea here is that since humanity is composed of lots of interacting intelligence sociotechnical organizations, any hostile intelligence is going to have a lot of intelligent adversaries. If the game of life can be won through intelligence alone, then it can only be won with a really big intelligence advantage over other intelligent beings. It’s not about absolute intelligence, it’s intelligence inequality we need to worry about.
Consequently, the more intelligence advances (i.e, technologies) diffuse, the less risk there is.
Conclusion: The chance of an existential risk from an intelligence explosion is small and decreasing all the time.
So consider this: globally, there’s tons of investment in technologies that, when discovered, allow for local algorithmic intelligence explosions.
But even if we assume these algorithmic advances are nearly instantaneous, they are still bounded.
Lots of independent bounded explosions are happening all the time. But they are also diffusing all the time.
Since the global intelligence distribution is always fattening, that means that the chance of any particular technological advance granting a decisive advantage over others is decreasing.
There is always the possibility of a fluke, of course. But if there was going to be a humanity destroying technological discovery, it would probably have already been invented and destroyed us. Since it hasn’t, we have a lot more resilience to threats from intelligence explosions, not to mention a lot of other threats.
This doesn’t mean that it isn’t worth trying to figure out how to make AI better for people. But it does diminish the need to think about artificial intelligence as an existential risk. It makes AI much more comparable to a biological threat. Biological threats could be really bad for humanity. But there’s also the organic reality that life is very resilient and human life in general is very secure precisely because it has developed so much intelligence.
I believe that thinking about the risks of artificial intelligence as analogous to the risks from biological threats is helpful for prioritizing where research effort in artificial intelligence should go. Just because AI doesn’t present an existential risk to all of humanity doesn’t mean it doesn’t kill a lot of people or make their lives miserable. On the contrary, we are in a world with both a lot of artificial and non-artificial intelligence and a lot of miserable and dying people. These phenomena are not causally disconnected. A good research agenda for AI could start with an investigation of these actually miserable people and what their problems are, and how AI is causing that suffering or alternatively what it could do to improve things. That would be an enormously more productive research agenda than one that aims primarily to reduce the impact of potential explosions which are diminishingly unlikely to occur.

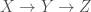 , then
, then  , where here
, where here 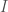 stands for mutual information. Mutual information is a measure of how much two random variables carry information about each other. If $I(X,Y) = 0$, that means the variables are independent. $I(X,Y) \geq 0$ always–that’s just a mathematical fact about how it’s defined.
stands for mutual information. Mutual information is a measure of how much two random variables carry information about each other. If $I(X,Y) = 0$, that means the variables are independent. $I(X,Y) \geq 0$ always–that’s just a mathematical fact about how it’s defined.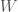 and there’s am organism, or a person, or a sociotechnical organization within it,
and there’s am organism, or a person, or a sociotechnical organization within it, 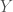 . The world is big and complex, which implies that it has a lot of informational entropy,
. The world is big and complex, which implies that it has a lot of informational entropy, 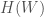 . Through whatever sensory apparatus is available to
. Through whatever sensory apparatus is available to  . This in turn bounds the mutual information between the organism and the world:
. This in turn bounds the mutual information between the organism and the world: 
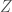 depend only on its internal state. It is an agent, reacting to its environment. Well whatever these actions are, they can only be so calibrated to the world as the agent had capacity to absorb the world’s information. I.e.,
depend only on its internal state. It is an agent, reacting to its environment. Well whatever these actions are, they can only be so calibrated to the world as the agent had capacity to absorb the world’s information. I.e.,  . The implication is that the more limited the mental capacity of the organism, the more its actions will be approximately independent of the state of the world that precedes it.
. The implication is that the more limited the mental capacity of the organism, the more its actions will be approximately independent of the state of the world that precedes it. 


 is the posterior probability of a hypothesis
is the posterior probability of a hypothesis  given observed data
given observed data 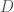 . If one is following statistically optimal procedure, one can compute this value by taking the prior probability of the hypothesis
. If one is following statistically optimal procedure, one can compute this value by taking the prior probability of the hypothesis  , multiplying it by the likelihood of the data given the hypothesis
, multiplying it by the likelihood of the data given the hypothesis  , and then normalizing this result by dividing by the probability of the data over all models,
, and then normalizing this result by dividing by the probability of the data over all models, 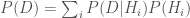 .
.
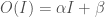 for some parameters
for some parameters 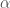 and
and  , where
, where 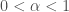 and
and  , then we can compute:
, then we can compute:
 . This is the “intelligence explosion” that gives Bostrom’s argument so much momentum. The explosion only gets worse if recalcitrance is below a constant.
. This is the “intelligence explosion” that gives Bostrom’s argument so much momentum. The explosion only gets worse if recalcitrance is below a constant.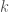 . Keep in mind that the y-axis is plotted on a log scale, which means that a roughly linear increase indicates exponential growth.
. Keep in mind that the y-axis is plotted on a log scale, which means that a roughly linear increase indicates exponential growth.

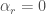 . Plugging in several values for these parameters and plotting again with the y-scale on the log axis, we get:
. Plugging in several values for these parameters and plotting again with the y-scale on the log axis, we get:
