
Practical social forecasting
I was once long ago asked to write a review of Philip Tetlock’s Expert Political Judgment: How Good Is It? How Can We Know? (2006) and was, like a lot of people, very impressed. If you’re not familiar with the book, the gist is that Tetlock, a psychologist, runs a 20 year study asking everybody who could plausibly be called a “political expert” to predict future events, and then scores them using a very reasonable Bayesian scoring system. He then searches the data for insights about what makes for good political forecasting ability. He finds it to be quite rare, but correlated with humbler and more flexible styles of thinking. Tetlock has gone on to pursue and publish about this line of research. There are now forecasting competitions, and the book Superforecasting. Tetlock has a following.
What I caught my attention in the original book, which was somewhat downplayed in the research program as a whole, is that rather simple statistical models, with two or three regressed variables, performed very well in comparison to even the best human experts. In a Bayesian sense, they were at least as good as the best people. These simple models tended towards guessing something close to the base rate of an event, whereas even the best humans tended to believe their own case-specific reasoning somewhat more than they perhaps should have.
This could be seen as a manifestation of the “bias/variance tradeoff” in (machine and other) learning. A learning system must either have a lot of concentration in the probability mass of its prior (bias) or it must spread this mass quite thin (variance). Roughly, a learning system is a good one for its context if, and maybe only if, its prior is a good enough fit for the environment that it’s in. There’s no free lunch. So the only way to improve social scientific forecasting is to encode more domain specific knowledge into the learning system. Or so I thought until recently.
For the past few years I have been working on computational economics tools that enable modelers to imagine and test theories about the dynamics behind our economic observations. This is a rather challenging and rewarding field to work in, especially right now, when the field of Economics is rapidly absorbing new idea from computer science and statistics. Last August, I had the privilege to attend a summer school and conference on the theme of “Deep Learning for Solving and Estimating Dynamic Models” put on by the Econometric Society DSE Summer School. It was awesome.
The biggest, least subtle, takeaway from the summer school and conference is that deep learning is going to be a big deal for Economics, because these techniques make it feasible to solve and estimate models with much higher dimensionality than has been possible with prior methods. By “solve”, I mean coming to conclusions, for a given model of a bunch of agents interacting with each other through, for example, a market, with some notion of their own reward structure, what the equilibrium dynamics of that system are. Solving these kinds of stochastic dynamic control problems, especially when there is nontrivial endogenous aggregation of agent behavior, is computationally quite difficult. But there are cool ways of encoding the equilibrium conditions of the model, or the optimality conditions of the agents involved, into the loss function of a neural network so that the deep learning training architecture works as a model solver. By “estimate”, I mean identify, for a give model, the parameterization of the model that produces results that make some empirical calibration targets maximally likely.
But maybe more foundationally exciting than seeing these results — which were very great — was the work that demonstrated some practical consequences of the double descent phenomenon in deep learning.

Double descent has been discussed, I guess, since 2018 but it has only recently gotten on my radar. It explains a lot about how and why deep learning has blown so many prior machine learning results out of the water. The core idea is that when a neural network is overparameterized — has so many degrees of freedom that, when trained, it can entirely interpolate (reproduce) the training data — it begins to perform better than any underparameterized model.
The underlying reasons for this are deep and somewhat mysterious. I have an intuition about it that I’m not sure checks out properly mathematically, but I will jot it down here anyway. There are some results suggesting that an infinitely parameterized neural network, of a certain kind, is equivalent to a Gaussian Process, a collection of random variables such that any infinite collection of them is a multivariate normal distribution. If the best model that we can ever train is an even largely and more complex Gaussain process, then this suggests that the Central Limit Theorem is once again the rule that explains the world as we see it, but in a far more textured and interesting way than is obvious. The problem with the Central Limit Theory and normal distributions is that they are not explainable — the explanation for the phenomenon is always a plethora of tiny factors, none of which are sufficient individually. And yet, because it is a foundational mathematical rule, it is always available as an explanation for any phenomenon we can experience. A perfect null hypothesis. Which turns out to be the best forecasting tool available?
It’s humbling material to work with, in any case.
References
Azinovic, Marlon and Gaegauf, Luca and Scheidegger, Simon, Deep Equilibrium Nets (May 24, 2019). Available at SSRN: https://ssrn.com/abstract=3393482 or http://dx.doi.org/10.2139/ssrn.3393482
Kelly, Bryan T. and Malamud, Semyon and Zhou, Kangying, The Virtue of Complexity in Return Prediction (December 13, 2021). Swiss Finance Institute Research Paper No. 21-90, Journal of Finance, forthcoming, Available at SSRN: https://ssrn.com/abstract=3984925 or http://dx.doi.org/10.2139/ssrn.3984925
Nakkiran, P., Kaplun, G., Bansal, Y., Yang, T., Barak, B. and Sutskever, I., 2021. Deep double descent: Where bigger models and more data hurt. Journal of Statistical Mechanics: Theory and Experiment, 2021(12), p.124003.




 which dictates that the output of the mechanism depends only slightly on any one individual data subject’s data. This is most often expressed mathematically as
which dictates that the output of the mechanism depends only slightly on any one individual data subject’s data. This is most often expressed mathematically as![Pr[A(D_1) \in S] \leq e^\epsilon \cdot Pr[A(D_2) \in S]](https://s0.wp.com/latex.php?latex=Pr%5BA%28D_1%29+%5Cin+S%5D+%5Cleq+e%5E%5Cepsilon+%5Ccdot+Pr%5BA%28D_2%29+%5Cin+S%5D&bg=fff&fg=444444&s=0&c=20201002)
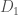 and
and  differ only by the contents on one data point corresponding to a single individual, and
differ only by the contents on one data point corresponding to a single individual, and 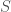 is any arbitrary set of outputs of the mechanism.
is any arbitrary set of outputs of the mechanism. .
.