Complex systems and ethics according to contextual integrity
Complex systems theory is a way of thinking about systems with many interacting parts and functions. It draws on physics and the science of modeling dynamic systems. It’s a trans-disciplinary, quantitative science of everything. It often and increasingly gets applied to social systems, often through the methods of agent-based modeling (ABM). ABM has a long history in computational sociology. More recently, it has made inroads into economics and finance (Axtell and Farmer, 2022). That’s important intellectual territory to win over because, of course, it is vitally important for both private and public interests. Its progress there is gradual but steady. ABM and complex systems methods have no dogma besides mathematical and computational essentials. Their eventual triumph is more or less assured. As I’ve argued, ABM and complex systems theory are thus an exciting frontier for legal theory (Benthall and Strandburg, 2021). For these reasons, one line of my research is involved in developing computational frameworks (i.e. software libraries, mathematical scaffolding) for computational social scientific modeling.
Contextual Integrity (CI) is an ethical theory developed by Helen Nissenbaum. It is especially applicable to questions of the ethics of information technology and computation. Central to the theory is the idea of “appropriate information flow”, or flows of (personal) information which conform with “information norms”. According to CI, information norms are legitimized by a balance of societal values, contextual purposes, and individual ends. The work of the CI ethicist is to wrestle with the alignments and contradictions between these alignments, purposes, and ends to identify the most legitimate norms for a given context,. When the legitimate norms are identified, it is then in principle possible to design and deploy technology in accordance with these norms.
CI is a philosophy grounded in social theory. It has never been robustly quantified and many people think this is impossible to do. I’m not among these people. In fact, much of my work is about trying to quantify or model CI. It should come as no surprise, then, that I now see CI in terms of complexity theory. It has struck me recently that what this amounts to, more or less, is a computational social theory of ethics! This idea is exciting to me, and one day I’ll want to write it down in detail. For now, I have some nice diagrams and notes from a recent presentation I wanted to share.
CI is a theory of ethics that is ultimately concerned with the way that values, purposes, and ends legitimize socially understood practices. The ethicist’s job, for CI, is to design legitimate institutions. A problem for the ethicist is that some institutions can be legitimate, but utopian, in that they are not stable behavioral patterns for the sociotechnical system. Complex systems theory, as a descriptive science, is well adapted to modeling systems and identifying the regular behaviors within them, under varying conditions. Borrowing a notion from physics, a system can exhibit many regular behavioral states, which we might call phases. For example, it is well known that water has many different phases, depending on the temperature: ice, the liquid water, steam, etc.

Norms have both descriptive and (ahem) normative dimensions. (This confusing jargon is part of why it’s so hard to make progress in this area.) In other words, for there to be an actually existing norm, it has to be both regular and, to be ethical according to CI, legitimate.
There are critics of CI who argue that one problem with it is that it assumes an apolitical consensus of information norms without addressing how norms might be distorted by, e.g., power in society. This is not terribly fair to Nissenbaum’s broader corpus of work, which certainly acknowledges political complexity (see for example the recent Nissenbaum, 2024). Suffice it to say here that not all individual end up being ‘legitimized’ when ethicists assess things, and that legitimization is always political. Moreover, individual ends and politics can, of course, often be the driver of system behavior away from legitimate institutions. We can’t always have nice things.
Nevertheless, it remains useful to consider how and under what conditions a system could remain legitimate despite technological change. This is what the original CI design heuristic is: a procedure for evaluating what to do when a new technology creates a disruptive change in societal information flows.

Ideally, for CI, when a new technology destabilizes the sociotechnical system’s behavior and threatens it with illegitimate practices, society reacts (through journalism, through ethics, through a political process, through private choices and actions, etc.) and returns the system to a regular behavioral pattern that is legitimate. This might not be the same behavior as the system started with. It might be even better. And that’s OK.
What’s bad, for CI, is if the system gets stuck in an illegitimate but still robust phase.

While there are some applications of CI that serve anodyne ends of parsing and implementing uncontroversial privacy rules, there are other uses of CI as a radical critique of the status quo. This is well exemplified by Ido Sivan-Sevilla et al.’s comments on the FTC ANPR on Commercial Surveillance and Lax Data Security Practices (2022), which is a succinct and to-the-point condemnation of the “notice and consent” practices in commercial surveillance. We live in a world in which standard, even ubiquitous, technology norms depend on “laughable legal fictions” such as the idea that users of web services are legitimate parties to contracts with vendors. It is well documented how these fictions have been enshrined into law by decades of pressure by the technology sector in courts and government (Cohen, 2019).
Together, CI and complex systems theory can show how society can be a winner, or loser, beyond the sum of individual outcomes. There are certainly those that have argued that, essentially, “there is no such thing as society”, and that voluntary, binary transactions between parties are all there is. An anarchic, libertarian, or laissez-faire system certainly serves the individual ends of some, and is to some extent stable until the lords of anarchy create new systems of rules that are in their interest. It is difficult to analyze the social costs of these political changes in terms of “individual harms”, because the true marginal cost is not measurable at the level of the individual, but rather at the level of the phase transition. A complex systems theory allows for this broader view of what is at stake.
This approach also, I think, helps convey the fragility of legitimate institutions. Nothing guarantees legitimacy. Legitimate institutions typically constrain the behavior of some actors in ways that they individually do not enjoy. There are social processes which can steer a system towards a more legitimate phase, but these will meet with resistance, sometimes fail, and can be coopted by bad faith actors serving their own ends.
Indeed, there are those who would say we do not live in a legitimate system and have not lived in one for a long time. “Legitimate for whom?” Even if this is so, CI invites us to have a productive dialog about what legitimacy would entail, by sorting out different motivations and looking at the options for balancing them out. This good faith search for resolutions is often thankless and unrewarded, but certainly we would be worse off without it. On the other hand, arguments about legitimate institutions that are divorced from realistic understandings of sociotechnical processes are easily deployed as propaganda and ideology to cover illegitimate behavior. Ethics requires a science of sociotechnical systems; sociotechnical systems are complex; complex systems theory is a solid foundation for such a science.
References
Axtell, R. L., & Farmer, J. D. (2022). Agent-based modeling in economics and finance: Past, present, and future. Journal of Economic Literature, 1-101.
Benthall, S., & Strandburg, K. J. (2021). Agent-based modeling as a legal theory tool. Frontiers in Physics, 9, 666386.
Cohen, J. E. (2019). Between truth and power. Oxford University Press.
Nissenbaum, H. (2024). AI Safety: A Poisoned Chalice?. IEEE Security & Privacy, 22(2), 94-96.
 which dictates that the output of the mechanism depends only slightly on any one individual data subject’s data. This is most often expressed mathematically as
which dictates that the output of the mechanism depends only slightly on any one individual data subject’s data. This is most often expressed mathematically as![Pr[A(D_1) \in S] \leq e^\epsilon \cdot Pr[A(D_2) \in S]](https://s0.wp.com/latex.php?latex=Pr%5BA%28D_1%29+%5Cin+S%5D+%5Cleq+e%5E%5Cepsilon+%5Ccdot+Pr%5BA%28D_2%29+%5Cin+S%5D&bg=fff&fg=444444&s=0&c=20201002)
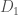 and
and  differ only by the contents on one data point corresponding to a single individual, and
differ only by the contents on one data point corresponding to a single individual, and 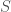 is any arbitrary set of outputs of the mechanism.
is any arbitrary set of outputs of the mechanism. .
.