
Ashby’s Law and AI control
I’ve recently discovered Ashby’s Law, also know as the First Law of Cybernetics, by reading Stafford Beer’s “Designing Freedom” lectures. Ashby’s Law is a powerful idea, one I’ve been grasping at intuitively for some time. For example, here I was looking for something like it and thought I could get it from the Data Processing Inequality in information theory. I have not yet grokked the mathematical definition of Ashby’s Law, which I gather is in Ross Ashby’s An Introduction to Cybernetics. Though I am not sure yet, I expect the formulation there can use an update. But if I am right about its main claims, I think the argument of this post will stand.
Ashby’s Law is framed in terms of ‘variety’, which is the number of states that it is possible for a system to be in. A six-sided die has six possible states (if you’re just looking at the top of it). A laptop has many more. A brain has many more even than that. A complex organization with many people in it, all with laptops, has even more. And so on.
The law can be stated in many ways. One of them is that:
When the variety or complexity of the environment exceeds the capacity of a system (natural or artificial) the environment will dominate and ultimately destroy that system.
The law is about the relationship between a system and its environment. Or, in another sense, it is about a system to be controlled and a different system that tries to control that system. The claim is that the control unit needs to have at least as much variety as the system to be controlled for it to be effective.
This reminds me of an argument I had with a superintelligence theorist back when I was thinking about such things. The Superintelligence people, recall, worry about an AI getting the ability to improve itself recursively and causing an “intelligence explosion”. Its own intelligence, so to speak, explodes, surpassing all other intelligent life and giving it total domination over the fate of humanity.
Here is the argument that I posed a few years ago, reframed in terms of Ashby’s Law:
- The AI in question is a control unit, C, and the world it would control is the system, S.
- For the AI to have effective domination over S, C would need at least as much variety as S.
- But S includes C within it. The control unit is part of the larger world.
- Hence, no C can perfectly control S.
Superintelligence people will no doubt be unsatisfied by this argument. The AI need not be effective in the sense dictated by Ashby’s Law. It need only be capable of outmaneuvering humans. And so on.
However, I believe the argument gets at why it is difficult for complex control systems to ever truly master the world around them. It is very difficult for a control system to have effective control over itself, let alone itself in a larger systemic context, without some kind of order constraining the behavior of the total system (the system including the control unit) imposed from without. The idea that it is possible to gain total mastery or domination through an AI or better data systems is a fantasy because the technical controls adds their own complexity to the world that is to be controlled.
This is a bit of a paradox, as it raises the question of how any control unites work at all. I’ll leave this for another day.
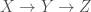 , then
, then  , where here
, where here 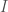 stands for mutual information. Mutual information is a measure of how much two random variables carry information about each other. If $I(X,Y) = 0$, that means the variables are independent. $I(X,Y) \geq 0$ always–that’s just a mathematical fact about how it’s defined.
stands for mutual information. Mutual information is a measure of how much two random variables carry information about each other. If $I(X,Y) = 0$, that means the variables are independent. $I(X,Y) \geq 0$ always–that’s just a mathematical fact about how it’s defined.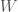 and there’s am organism, or a person, or a sociotechnical organization within it,
and there’s am organism, or a person, or a sociotechnical organization within it, 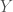 . The world is big and complex, which implies that it has a lot of informational entropy,
. The world is big and complex, which implies that it has a lot of informational entropy, 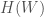 . Through whatever sensory apparatus is available to
. Through whatever sensory apparatus is available to  . This in turn bounds the mutual information between the organism and the world:
. This in turn bounds the mutual information between the organism and the world: 
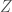 depend only on its internal state. It is an agent, reacting to its environment. Well whatever these actions are, they can only be so calibrated to the world as the agent had capacity to absorb the world’s information. I.e.,
depend only on its internal state. It is an agent, reacting to its environment. Well whatever these actions are, they can only be so calibrated to the world as the agent had capacity to absorb the world’s information. I.e.,  . The implication is that the more limited the mental capacity of the organism, the more its actions will be approximately independent of the state of the world that precedes it.
. The implication is that the more limited the mental capacity of the organism, the more its actions will be approximately independent of the state of the world that precedes it. 