
Credit scores and information economics
The recent Equifax data breach brings up credit scores and their role in the information economy. Credit scoring is a controversial topic in the algorithmic accountability community. Frank Pasquale, for example, writes about it in The Black Box Society. Most of the critical writing on the subject points to how credit scoring might be done in a discriminatory or privacy-invasive way. As interesting as those critiques are from a political and ethical perspective, it’s worth reviewing what credit scores are for in the first place.
Let’s model this as we have done in other cases of information flow economics.
There’s a variable of interest, the likelihood that a potential borrower will not default on a loan, 

![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002)
There’s a decision to be made by a bank: whether or not to provide a random borrower a loan.
To keep things very simple, let’s suppose that the bank gets a payoff of 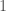

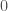
Given a particular
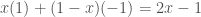
Given the domain of 
We can now consider welfare outcomes under conditions of now information flow, total information flow, and partial information flow.
Suppose the bank has no insight into ![E[2x+1]](https://s0.wp.com/latex.php?latex=E%5B2x%2B1%5D&bg=fff&fg=444444&s=0&c=20201002)
If the bank has total insight into
It also increases the utility of the bank. This is perhaps best illustrated with a simple example. Suppose the distribution

which is a significant improvement over the expected payoff of 0 in the uninformed case.
Putting off an analysis of the partial information case for now, suffice it to say that we expect partial information (such as a credit score) to lead to an intermediate result, improving bank profits and differentiating borrowers with respect to the bank’s choice to loan.
What is perhaps most interesting about this analysis is the similarity between it and Posner’s employment market. In both cases, the subject of the variable of interest
References
Blöchlinger, A., & Leippold, M. (2006). Economic benefit of powerful credit scoring. Journal of Banking & Finance, 30(3), 851-873.
