
The recalcitrance of prediction
We have identified how Bostrom’s core argument for superintelligence explosion depends on a crucial assumption. An intelligence explosion will happen only if the kinds of cognitive capacities involved in instrumental reason are not recalcitrant to recursive self-improvement. If recalcitrance rises comparably with the system’s ability to improve itself, then the takeoff will not be fast. This significantly decreases the probability of decisively strategic singleton outcomes.
In this section I will consider the recalcitrance of intelligent prediction, which is one of the capacities that is involved in instrumental reason (another being planning). Prediction is a very well-studied problem in artificial intelligence and statistics and so is easy to characterize and evaluate formally.
Recalcitrance is difficult to formalize. Recall that in Bostrom’s formulation:

One difficulty in analyzing this formula is that the units are not specified precisely. What is a “unit” of intelligence? What kind of “effort” is the unit of optimization power? And how could one measure recalcitrance?
A benefit of looking at a particular intelligent task is that it allows us to think more concretely about what these terms mean. If we can specify which tasks are important to consider, then we can take the level of performance on those well-specified class of problems as measures of intelligence.
Prediction is one such problem. In a nutshell, prediction comes down to estimating a probability distribution over hypotheses. Using the Bayesian formulation of statistical influence, we can represent the problem as:

Here, 

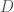


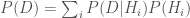
Statisticians will justifiably argue whether this is the best formulation of prediction. And depending on the specifics of the task, the target value may well be some function of posterior (such as the hypothesis with maximum likelihood) and the overall distribution may be secondary. These are valid objections that I would like to put to one side in order to get across the intuition of an argument.
What I want to point out is that if we look at the factors that affect performance on prediction problems, there a very few that could be subject to algorithmic self-improvement. If we think that part of what it means for an intelligent system to get more intelligent is to improve its ability of prediction (which Bostrom appears to believe), but improving predictive ability is not something that a system can do via self-modification, then that implies that the recalcitrance of prediction, far from being constant or lower, actually approaches infinity with respect the an autonomous system’s capacity for algorithmic self-improvement.
So, given the formula above, in what ways can an intelligent system improve its capacity to predict? We can enumerate them:
- Computational accuracy. An intelligent system could be better or worse at computing the posterior probabilities. Since most of the algorithms that do this kind of computation do so with numerical approximation, there is the possibility of an intelligent system finding ways to improve the accuracy of this calculation.
- Computational speed. There are faster and slower ways to compute the inference formula. An intelligent system could come up with a way to make itself compute the answer faster.
- Better data. The success of inference is clearly dependent on what kind of data the system has access to. Note that “better data” is not necessarily the same as “more data”. If the data that the system learns from is from a biased sample of the phenomenon in question, then a successful Bayesian update could make its predictions worse, not better. Better data is data that is informative with respect to the true process that generated the data.
- Better prior. The success of inference depends crucially on the prior probability assigned to hypotheses or models. A prior is better when it assigns higher probability to the true process that generates observable data, or models that are ‘close’ to that true process. An important point is that priors can be bad in more than one way. The bias/variance tradeoff is well-studied way of discussing this. Choosing a prior in machine learning involves a tradeoff between:
- Bias. The assignment of probability to models that skew away from the true distribution. An example of a biased prior would be one that gives positive probability to only linear models, when the true phenomenon is quadratic. Biased priors lead to underfitting in inference.
- Variance.The assignment of probability to models that are more complex than are needed to reflect the true distribution. An example of a high-variance prior would be one that assigns high probability to cubic functions when the data was generated by a quadratic function. The problem with high variance priors is that they will overfit data by inferring from noise, which could be the result of measurement error or something else less significant than the true generative process.
In short, there best prior is the correct prior, and any deviation from that increases error.
Now that we have enumerate the ways in which an intelligent system may improve its power of prediction, which is one of the things that’s necessary for instrumental reason, we can ask: how recalcitrant are these factors to recursive self-improvement? How much can an intelligent system, by virtue of its own intelligence, improve on any of these factors?
Let’s start with computational accuracy and speed. An intelligent system could, for example, use some previously collected data and try variations of its statistical inference algorithm, benchmark their performance, and then choose to use the most accurate and fastest ones at a future time. Perhaps the faster and more accurate the system is at prediction generally, the faster and more accurately it would be able to engage in this process of self-improvement.
Critically, however, there is a maximum amount of performance that one can get from improvements to computational accuracy if you hold the other factors constant. You can’t be more accurate than perfectly accurate. Therefore, at some point recalcitrance of computational accuracy rises to infinity. Moreover, we would expect that effort made at improving computational accuracy would exhibit diminishing returns. In other words, recalcitrance of computational accuracy climbs (probably close to exponentially) with performance.
What is the recalcitrance of computational speed at inference? Here, performance is limited primarily by the hardware on which the intelligent system is implemented. In Bostrom’s account of superintelligence explosion, he is ambiguous about whether and when hardware development counts as part of a system’s intelligence. What we can say with confidence, however, is that for any particular piece of hardware there will be a maximum computational speed attainable with with, and that recursive self-improvement to computational speed can at best approach and attain this maximum. At that maximum, further improvement is impossible and recalcitrance is again infinite.
What about getting better data?
Assuming an adequate prior and the computational speed and accuracy needed to process it, better data will always improve prediction. But it’s arguable whether acquiring better data is something that can be done by an intelligent system working to improve itself. Data collection isn’t something that the intelligent system can do autonomously, since it has to interact with the phenomenon of interest to get more data.
If we acknowledge that data collection is a critical part of what it takes for an intelligent system to become more intelligent, then that means we should shift some of our focus away from “artificial intelligence” per se and onto ways in which data flows through society and the world. Regulations about data locality may well have more impact on the arrival of “superintelligence” than research into machine learning algorithms now that we have very faster, very accurate algorithms already. I would argue that the recent rise in interest in artificial intelligence is due mainly to availability of vast amounts of new data through sensors and the Internet. Advances in computational accuracy and speed (such as Deep Learning) have to catch up to this new availability of data and use new hardware, but data is the rate limiting factor.
Lastly, we have to ask: can a system improve its own prior, if data, computational speed, and computational accuracy are constant?
I have to argue that it can’t do this in any systematic way, if we are looking at the performance of the system at the right level of abstraction. Potentially a machine learning algorithm could modify its prior if it sees itself as underperforming in some ways. But there is a sense in which any modification to the prior made by the system that is not a result of a Bayesian update is just part of the computational basis of the original prior. So recalcitrance of the prior is also infinite.
We have examined the problem of statistical inference and ways that an intelligent system could improve its performance on this task. We identified four potential factors on which it could improve: computational accuracy, computational speed, better data, and a better prior. We determined that contrary to the assumption of Bostrom’s hard takeoff argument, the recalcitrance of prediction is quite high, approaching infinity in the cases of computational accuracy, computational speed, and the prior. Only data collections to be flexibly recalcitrant. But data collection is not a feature of the intelligent system alone but also depends on its context.
As a result, we conclude that the recalcitrance of prediction is too high for an intelligence explosion that depends on it to be fast. We also note that those concerned about superintelligent outcomes should shift their attention to questions about data sourcing and storage policy.

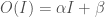 for some parameters
for some parameters 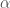 and
and  , where
, where 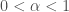 and
and  , then we can compute:
, then we can compute:
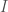 will be exponentially increasing in time
will be exponentially increasing in time  . This is the “intelligence explosion” that gives Bostrom’s argument so much momentum. The explosion only gets worse if recalcitrance is below a constant.
. This is the “intelligence explosion” that gives Bostrom’s argument so much momentum. The explosion only gets worse if recalcitrance is below a constant.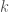 . Keep in mind that the y-axis is plotted on a log scale, which means that a roughly linear increase indicates exponential growth.
. Keep in mind that the y-axis is plotted on a log scale, which means that a roughly linear increase indicates exponential growth.

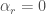 . Plugging in several values for these parameters and plotting again with the y-scale on the log axis, we get:
. Plugging in several values for these parameters and plotting again with the y-scale on the log axis, we get:
