
Recalcitrance examined: an analysis of the potential for superintelligence explosion
by Sebastian Benthall
To recap:
- We have examined the core argument from Nick Bostrom’s Superintelligence: Paths, Dangers, Strategies regarding the possibility of a decisively strategic superintelligent singleton–or, more glibly, an artificial intelligence that takes over the world.
- With an eye to evaluating whether this outcome is particularly likely relative to other futurist outcomes, we have distilled the argument and in so doing have reduced it to a simpler problem.
- That problem is to identify bounds on the recalcitrance of the capacities that are critical for instrumental reasoning. Recalcitrance is defined as the inverse of the rate of increase to intelligence per time per unit of effort put into increasing that intelligence. It is meant to capture how hard it is to make an intelligent system smarter, and in particular how hard it is for an intelligent system to make itself smarter. Bostrom’s argument is that if an intelligent system’s recalcitrance is constant or lower, then it is possible for the system to undergo an “intelligence explosion” and take over the world.
- By analyzing how Bostrom’s argument depends only on the recalcitrance of instrumentality, and not of the recalcitrance of intelligence in general, we can get a firmer grip on the problem. In particular, we can focus on such tasks as prediction and planning. If we discover that these tasks are in fact significantly recalcitrant that should reduce our expected probability of an AI singleton and consequently cause us to divert research funds to problems that anticipate other outcomes.
In this section I will look in further depth at the parts of Bostrom’s intelligence explosion argument about optimization power and recalcitrance. How recalcitrant must a system be for it to not be susceptible to an intelligence explosion?
This section contains some formalism. For readers uncomfortable with that, trust me: if the system’s recalcitrance is roughly proportional to the amount that the system is able to invest in its own intelligence, then the system’s intelligence will not explode. Rather, it will climb linearly. If the system’s recalcitrance is significantly greater than the amount that the system can invest in its own intelligence, then the system’s intelligence won’t even climb steadily. Rather, it will plateau.
To see why, recall from our core argument and definitions that:
Rate of change in intelligence = Optimization power / Recalcitrance.
Optimization power is the amount of effort that is put into improving the intelligence of system. Recalcitrance is the resistance of that system to improvement. Bostrom presents this as a qualitative formula then expands it more formally in subsequent analysis.

Bostrom’s claim is that for instrumental reasons an intelligent system is likely to invest some portion of its intelligence back into improving its intelligence. So, by assumption we can model 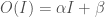
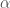

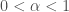


Under these conditions, 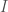

In order to illustrate how quickly the “superintelligence takeoff” occurs under this model, I’ve plotted the above function plugging in a number of values for the parameters 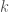

Modeled superintelligence takeoff where rate of intelligence gain is linear in current intelligence and recalcitrance is constant. Slope in the log scale is determine by alpha and k values.
It is true that in all the above cases, the intelligence function is exponentially increasing over time. The astute reader will notice that by my earlier claim
However, it’s important to remember that recalcitrance may also be a function of intelligence. Bostrom does not mention the possibility of recalcitrance being increasing in intelligence. How sensitive to intelligence would recalcitrance need to be in order to prevent exponential growth in intelligence?
Consider the following model where recalcitrance is, like optimization power, linearly increasing in intelligence.

Now there are four parameters instead of three. Note this model is identical to the one above it when 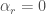

Plot of takeoff when both optimization power and recalcitrance are linearly increasing in intelligence. Only when recalcitrance is unaffected by intelligence level is there an exponential takeoff. In the other cases, intelligence quickly plateaus on the log scale. No matter how much the system can invest in its own optimization power as a proportion of its total intelligence, it still only takes off at a linear rate.
The point of this plot is to illustrate how easily exponential superintelligence takeoff might be stymied by a dependence of recalcitrance on intelligence. Even in the absurd case where the system is able to invest a thousand times as much intelligence that it already has back into its own advancement, and a large team steadily commits a million “units” of optimization power (whatever that means–Bostrom is never particularly clear on the definition of this), a minute linear dependence of recalcitrance on optimization power limits the takeoff to linear speed.
Are the reasons to think that recalcitrance might increase as intelligence increases? Prima facie, yes. Here’s a simple thought experiment: What if there is some distribution of intelligence algorithm advances that are available in nature and that some of them are harder to achieve than others. A system that dedicates itself to advancing its own intelligence, knowing that it gets more optimization power as it gets more intelligent, might start by finding the “low hanging fruit” of cognitive enhancement. But as it picks the low hanging fruit, it is left with only the harder discoveries. Therefore, recalcitrance increases as the system grows more intelligent.
This is not a decisive argument against fast superintelligence takeoff and the possibility of a decisively strategic superintelligent singleton. Above is just an argument about why it is important to consider recalcitrance carefully when making claims about takeoff speed, and to counter what I believe is a bias in Bostrom’s work towards considering unrealistically low recalcitrance levels.
In future work, I will analyze the kinds of instrumental intelligence tasks, like prediction and planning, that we have identified as being at the core of Bostrom’s superintelligence argument. The question we need to ask is: does the recalcitrance of prediction tasks increase as the agent performing them becomes better at prediction? And likewise for planning. If prediction and planning are the two fundamental components of means-ends reasoning, and both have recalcitrance that increases significantly with the intelligence of the agent performing them, then we have reason to reject Bostrom’s core argument and assign a very low probability to the doomsday scenario that occupies much of Bostrom’s imagination in Superintelligence. If this is the case, that suggests we should be devoting resources to anticipating what he calls multipolar scenarios, where no intelligent system has a decisive strategic advantage, instead.

Hey,
thank you for your thoughts. I have not yet found anyone to discuss this topic with so I rely on blogs as yours. How do we assume that there is something as ‘low hanging fruits’ for an AI? This seems to be the basis for your criticism, doesn’t it? As soon as I assume that intelligence is easily extendable for an AI, recalcitrance does not increase with intelligence any more and an explosion may occur. Moreover, as soon as something gets more intelligent, is it not possible to assume that fruits may be hanging even lower now? Or, to remain in the analogy, the system has gotten taller, hence more fruit can easily be reached. Please correct me if I am wrong…
On a formal note: For your first plot you assume alpha to be smaller than one, i.e. the system does not devote all its capacity to self-improvement. Is that a requirement? If so, your plots include an alpha=1.
I your second plot, alpha_r appears as alpha_o to my eyes ;)
Cheers,
Thomas.
Hello Thomas,
Thanks for your comment!
I think “intelligence is easily extendable for an AI” and “recalcitrance does not increase with intelligence” are roughly equivalent. If you assume that intelligence is easily extendable, then you will conclude that an explosion will occur.
In this blog post I am trying to show that that is a questionable assumption.
Sticking close to your analogy…I would say it is incorrect to say that if I somehow stand taller then all the fruit hangs lower. The difference between my height and the height of the fruit will be reduced, but that is different.
What’s at stake with the question of optimization power and recalcitrance is the relative rate of change of both your height and the height of the fruit, supposing eating fruit makes you taller.
Thanks for catching those! I don’t think it’s necessary for alpha to be smaller than one. I should correct that.