I’m still pondering the most recent Tufekci piece about algorithms and human judgment on Twitter. It prompted some grumbling among data scientists. Sweeping statements about ‘algorithms’ do that, since to a computer scientist ‘algorithm’ is about as general a term as ‘math’.
In later conversation, Tufekci clarified that when she was calling out the potential problems of algorithmic filtering of the Twitter newsfeed, she was speaking to the problems of a newsfeed curated algorithmically for the sake of maximizing ‘engagement’. Or ads. Or, it is apparent on a re-reading of the piece, new members. She thinks an anti-homophily algorithm would maybe be a good idea, but that this is so unlikely according to the commercial logic of Twitter to be a marginal point. And, meanwhile, she defends ‘human prioritizatin’ over algorithmic curation, despite the fact that homophily (not to mention preferential attachment) are arguable negative consequences of social system driven by human judgment.
I think inquiry into this question is important, but bound to be confusing to those who aren’t familiar in a deep way with network science, machine learning, and related fields. It’s also, I believe, helpful to have a background in cognitive science, because that’s a field which maintains that human judgment and computational systems are doing fundamentally commensurable kinds of work. When we think in sophisticated way about crowdsourced labor, we use this sort of thinking. We acknowledge, for example, that human brains are better at the computational task of image recognition, so then we employ Turkers to look at and label images. But those human judgments are then inputs to statistical processes that verify and check those judgments against each other. Later, those determinations that result from a combination of human judgment and algorithmic processing could be used in a search engine–which returns answers to questions based on human input. Search engines, then, are also a way of combining human and purely algorithmic judgment.
What it comes down to is that virtually all of our interactions with the internet are built around algorithmic affordances. And these systems can be understood systematically if we reject the quantitative/qualitative divide at the ontological level. Reductive physicalism entails this rejection, but–and this is not to be understated–pisses or alienates people who do qualitative or humanities research.
This is old news. C.P. Snow’s The Two Cultures. The Science Wars. We’ve been through this before. Ironically, the polarization is algorithmically visible in the contemporary discussion about algorithms.*

It’s I guess not surprising that STS and cultural studies academics are still around and in opposition to the hard scientists. What’s maybe new is how much computer science now affects the public, and how the popular press appears to have allied itself with the STS and cultural studies view. I guess this must be because cultural anthropologists and media studies people are more likely to become journalists and writers, whereas harder science is pretty abstruse.
There’s an interesting conflation now from the soft side of the culture wars of science with power/privilege/capitalism that plays out again and again. I bump into it in the university context. I read about it all the time. Tufekci’s pessimism that the only algorithmic filtering Twitter would adopt would be one that essentially obeys the logic “of Wall Street” is, well, sad. It’s sad that an unfortunate pairing that is analytically contingent is historically determined to be so.
But there is also something deeply wrong about this view. Of course there are humanitarian scientists. Of course there is a nuanced center to the science wars “debate”. It’s just that the tedious framing of the science wars has been so pervasive and compelling, like a commercial jingle, that it’s hard to feel like there’s an audience for anything more subtle. How would you even talk about it?
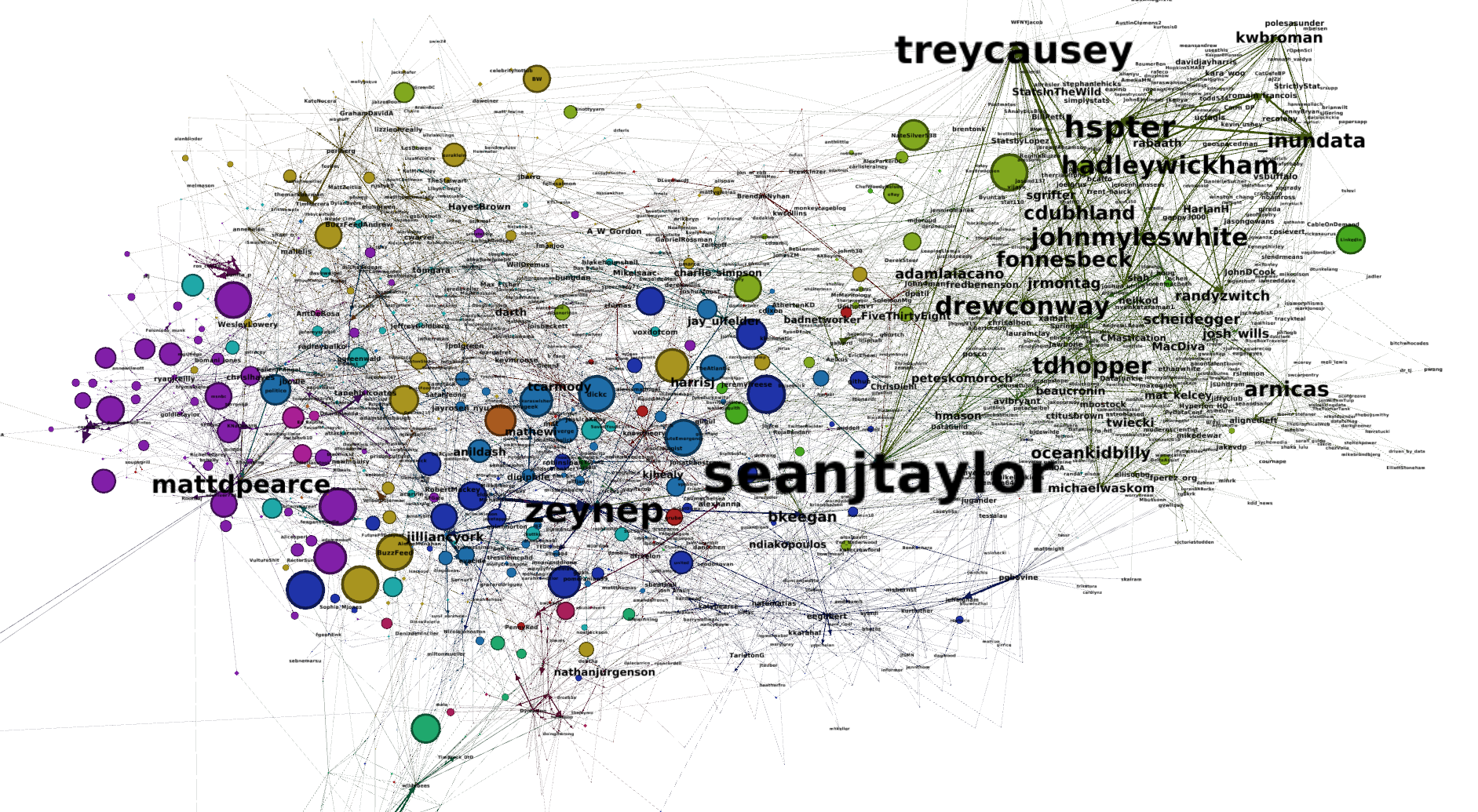
* I need to confess: I think there was some sloppiness in that Medium piece. If I had had more time, I would have done something to check which conversations were actually about the Tufekci article, and which were just about whatever. I feel I may have misrepresented this in the post. For the sake of accessibility or to make the point, I guess. Also, I’m retrospectively skittish about exactly how distinct a cluster the data scientists were, and whether its insularity might have been an artifact of the data collection method. I’ve been building out poll.emic in fits mainly as a hobby. I built it originally because I wanted to at last understand Weird Twitter’s internal structure. The results were interesting but I never got to writing them up. Now I’m afraid that the culture has changed so much that I wouldn’t recognize it any more. But I digress. Is it even notable that social scientists from different disciplines would have very different social circles around them? Is the generalization too much? And are there enough nodes in this graph to make it a significant thing to say about anything, really? There could be thousands of academic tiffs I haven’t heard about that are just as important but which defy my expectations and assumptions. Or is the fact that Medium appears to have endorsed a particular small set of public intellectuals significant? How many Medium readers are there? Not as many as there are Twitter users, by several orders of magnitude, I expect. Who matters? Do academics matter? Why am I even studying these people as opposed to people who do more real things? What about all the presumably sane and happy people who are not pathologically on the Internet? Etc.