
Economic costs of context collapse
One motivation for my recent studies on information flow economics is that I’m interested in what the economic costs are when information flows across the boundaries of specific markets.
For example, there is a folk theory of why it’s important to have data protection laws in certain domains. Health care, for example. The idea is that it’s essential to have health care providers maintain the confidentiality of their patients because if they didn’t then (a) the patients could face harm due to this information getting into the wrong hands, such as those considering them for employment, and (b) this would disincentivize patients from seeking treatment, which causes them other harms.
In general, a good approximation of general expectations of data privacy is that data should not be used for purposes besides those for which the data subjects have consented. Something like this was encoded in the 1973 Fair Information Practices, for example. A more modern take on this from contextual integrity (Nissenbaum, 2004) argues that privacy is maintained when information flows appropriately with respect to the purposes of its context.
A widely acknowledged phenomenon in social media, context collapse (Marwick and boyd, 2011; Davis and Jurgenson, 2014), is when multiple social contexts in which a person is involved begin to interfere with each other because members of those contexts use the same porous information medium. Awkwardness and sometimes worse can ensue. These are some of the major ways the world has become aware of what a problem the Internet is for privacy.
I’d like to propose that an economic version of context collapse happens when different markets interfere with each other through network-enabled information flow. The bogeyman of Big Brother through Big Data, the company or government that has managed to collect data about everything about you in order to infer everything else about you, has as much to do with the ways information is being used in cross-purposed ways as it has to do with the quantity or scope of data collection.
It would be nice to get a more formal grip on the problem. Since we’ve already used it as an example, let’s try to model the case where health information is disclosed (or not) to a potential employer. We already have the building blocks for this case in our model of expertise markets and our model of labor markets.
There are now two uncertain variables of interest. First, let’s consider a variety of health treatments 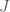
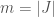
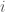


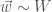
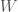
There is also the uncertain variable of how effective somebody will be at a job they are interested in. We’ll say this is distributed according to 
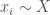
We will also say that
I must note here that I am not taking any position on whether or not employers should take disabilities into account when hiring people. I don’t even know for sure the consequences of this model yet. You could imagine this scenario taking place in a country which does not have the Americans with Disabilities Act and other legislation that affects situations like this.
As per the models that we are drawing from, let’s suppose that normal people don’t know how much they will benefit from different medical treatments; 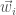
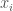

Let’s say person 

![\hat j = arg \max_{j \in J} E[X_j \vert y]](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j+%5Cvert+y%5D&bg=fff&fg=444444&s=0&c=20201002)
Now comes the tricky part. Let’s say the doctor is corrupt and willing to sell the medical records of her patients to her patient’s potential employers. By assumption 
We also know that having potential employers know more about your aptitudes is good for highly qualified applicants and bad for not as qualified applicants. The more information employers know about you, the more likely they will be able to tell if you are worth hiring.
The upshot is that there may be some patients who are more than happy to have their medical records sold off to their potential employers because those particular symptoms are correlated with high job performance. These will be attracted to systems that share their information across medical and employment purposes.
But for those with symptoms correlated with lower job performance, there is now a trickier decision. If doctors are corrupt, it may be that they choose not to reveal their symptoms accurately (or at all) because this information might hurt their chances of employment.
A few more wrinkles here. Suppose it’s true the fewer people will go to corrupt doctors because they suspect or know that information will leak to their employers. If there are people who suspect or know that the information that leaks to their employers will reflect on them favorably, that creates a selection effect on who goes to the doctor. This means that the information that
We can also add the possibility that not all doctors are corrupt. Only some are. But if it’s unknown which doctors are corrupt, the possibility of corruption still affects the strategies of patients/employees in a similar way, only now in expectation. Just as in the Akerlof market for lemons, a few corrupt doctors ruins the market.
I have not made these arguments mathematically specific. I leave that to a later date. But for now I’d like to draw some tentative conclusions about what mandating the protection of health information, as in HIPAA, means for the welfare outcomes in this model.
If doctors are prohibited from selling information to employers, then the two markets do not interfere with each other. Doctors can solicit symptoms in a way that optimizes benefits to all patients. Employers can make informed choices about potential candidates through an independent process. The latter will serve to select more promising applicants from less promising applicants.
But if doctors can sell health information to employers, several things change.
- Employers will benefit from information about employee health and offer to pay doctors for the information.
- Some doctors will discretely do so.
- The possibility of corrupt doctors will scare off those patients who are afraid their symptoms will reveal a lack of job aptitude.
- These patients no longer receive treatment.
- This reduces the demand for doctors, shrinking the health care market.
- The most able will continue to see doctors. If their information is shared with employers, they will be more likely to be hired.
- Employers may take having medical records available to be bought from corrupt doctors as a signal that the patient is hiding something that would reveal poor aptitude.
In sum, without data protection laws, there are fewer people receiving beneficial treatment and fewer jobs for doctors providing beneficial treatment. Employers are able to make more advantageous decisions, and the most able employees are able to signal their aptitude through the corrupt health care system. Less able employees may wind up being identified anyway through their non-participation in the medical system. If that’s the case, they may wind up returning to doctors for treatment anyway, though they would need to have a way of paying for it besides employment.
That’s what this model says, anyway. The biggest surprise for me is the implication that data protection laws serve this interests of service providers by expanding their customer base. That is a point that is not made enough! Too often, the need for data protection laws is framed entirely in terms of the interests of the consumer. This is perhaps a politically weaker argument, because consumers are not united in their political interest (some consumers would be helped, not harmed, by weaker data protection).
References
Akerlof, G. A. (1970). The market for” lemons”: Quality uncertainty and the market mechanism. The quarterly journal of economics, 488-500.
Davis, J. L., & Jurgenson, N. (2014). Context collapse: theorizing context collusions and collisions. Information, Communication & Society, 17(4), 476-485.
Marwick, A. E., & Boyd, D. (2011). I tweet honestly, I tweet passionately: Twitter users, context collapse, and the imagined audience. New media & society, 13(1), 114-133.
Nissenbaum, H. (2004). Privacy as contextual integrity. Wash. L. Rev., 79, 119.
