
Economics of expertise and information services
by Sebastian Benthall
We have no considered two models of how information affects welfare outcomes.
In the first model, inspired by an argument from Richard Posner, the are many producers (employees, in the specific example, but it could just as well be cars, etc.) and a single consumer. When the consumer knows nothing about the quality of the producers, the consumer gets an average quality producer and the producers split the expected utility of the consumer’s purchase equally. When the consumer is informed, she benefits and so does the highest quality producer, at the detriment of the other producers.
In the second example, inspired by Shapiro and Varian’s discussion of price differentiation in the sale of information goods, there was a single producer and many consumers. When the producer knows nothing about the “quality” of the consumers–their willingness to pay–the producer charges all consumers a profit-maximizing price. This price leaves many customers out of reach of the product, and many others getting a consumer surplus because the product is cheap relative to their demand. When the producer is more informed, they make more profit by selling as personalized prices. This lets the previously unreached customers in on the product at a compellingly low price. It also allows the producer to charge higher prices to willing customers; they capture what was once consumer surplus for themselves.
In both these cases, we have assumed that there is only one kind of good in play. It can vary numerically in quality, which is measured in the same units as cost and utility.
In order to bridge from theory of information goods to theory of information services, we need to take into account a key feature of information services. Consumers buy information when they don’t know what it is they want, exactly. Producers of information services tailor what they provide to the specific needs of the consumers. This is true for information services like search engines but also other forms of expertise like physician’s services, financial advising, and education. It’s notable that these last three domains are subject to data protection laws in the United States (HIPAA, GLBA, and FERPA) respectively, and on-line information services are an area where privacy and data protection are a public concern. By studying the economics of information services and expertise, we may discover what these domains have in common.
Let’s consider just a single consumer and a single producer. The consumer has a utility function 

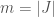

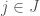
The catch is that the consumer does not know 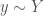
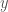
As in the other cases, let’s consider first the case where the acting party has no useful information about the particular customer. In this case, the producer has to choose their recommendation 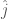
![\hat j = arg \max_{j \in J} E[X_j]](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002)
where 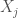
In the other extreme case, the producer has perfect information of the consumer’s utility function. They can pick the truly optimal product:
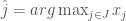
How much better off the consumer is in the second case, as opposed to the first, depends on the specifics of the distribution ![E[X_j]](https://s0.wp.com/latex.php?latex=E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002)
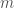

In the intermediate cases where the producer knows 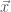
![\hat j = arg \max_{j \in J} E[X_j \vert y] =](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j+%5Cvert+y%5D+%3D&bg=fff&fg=444444&s=0&c=20201002)
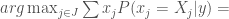

The precise values of the terms here depend on the distributions 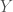


Note that in this model, it is the likelihood function 
