
Bridging between transaction cost and traditional economics
by Sebastian Benthall
Some time ago I was trying to get my head around transaction cost economics (TCE) because of its implications for the digital economy and cybersecurity. (1, 2, 3, 4, 5). I felt like I had a good grasp of the relevant theoretical claim of TCE which is the interaction between asset specificity and the make-or-buy decision. But I didn’t have a good sense of the mechanism that drove that claim.
I worked it out yesterday.
Recall that in the make or buy decision, a firm is determining whether or not to make some product in-house or to buy it from the market. This is a critical decision made by software and data companies, as often these businesses operate by assembling components and data streams into a new kind of service; these services often are the components and data streams used in other firms. And so on.
The most robust claim of TCE is that if the asset (component, service, data stream) is very specific to the application of the firm, then the firm will be more likely to make it. If the asset is more general-purpose, then it buy it as a commodity on the market.
Why is this? TCE does not attempt to describe this phenomenon in a mathematical model, at least as far as I have found. Nevertheless, this can be worked out with a much more general model of the economy.
Assume that for some technical component there are fix costs 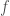
In case A, a vendor will have costs of 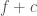
In case B, there’s broader market demand. It’s likely that there’s already multiple vendors in place who have made the fixed cost investment. The price to the buying firm is going to be closer to 
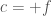
A few notes on the implications of this for the informational economy:
- Software libraries have high fixed cost and low marginal cost. The tendency of companies to tilt to open source cores with their products built on top is a natural result of the market. The modularity of open source software is in part explained by the ways “asset specificity” is shaped exogenously by the kinds of problems that need to be solved. The more general the problem, the more likely the solution has been made available open source. Note that there is still an important transaction cost at work here, the search cost. There’s just so many software libraries.
- Data streams can vary a great deal as to whether and how they are asset specific. When data streams are highly customized to the downstream buyer, they are specific; the customization is both costly to the vendor and adding value to the buyer. However, it’s rarely possible to just “make” data: it needs to be sourced from somewhere. When firms buy data, it is normally in a subscription model that takes into account industrial organization issues (such as lock in) within the pricing.
- Engineering talent, and related labor costs, are interesting in that for a proprietary system, engineering human capital gains tend to be asset specific, while for open technologies engineering skill is a commodity. The structure of the ‘tech business’, which requires mastery of open technology in order to build upon it a proprietary system, is a key dynamic that drives the software engineering practice.
There are a number of subtleties I’m missing in this account. I mentioned search costs in software libraries. There’s similar costs and concerns about the inherent riskiness of a data product: by definition, a data product is resolving some uncertainty with respect to some other goal or values. It must always be a kind of credence good. The engineering labor market is quite complex in no small part because it is exposed to the complexities of its products.
