1. Capital
Bourdieu nicely lays out a taxonomy of forms of capital (1986), including economic capital (wealth) which we are all familiar with, as well as cultural capital (skills, elite tastes) and social capital (relationships with others, especially other elites). By saying that all three categories are forms of capital, what he means is that each “is accumulated labor (in its materialized form or its ‘incorporated,’ embodied form) which, when appropriated on a private, i.e., exclusive, basis by agents or groups of agents, enables them to appropriate social energy in the form of reified or living labor.” In his account, capital in all its forms are what give society its structure, including especially its economic structure.
[Capital] is what makes the games of society – not least, the economic game – something other than simple games of chance offering at every moment the possibility of a miracle. Roulette, which holds out the opportunity of winning a lot of money in a short space of time, and therefore of changing one’s social status quasi-instantaneously, and in which the winning of the previous spin of the wheel can be staked and lost at every new spin, gives a fairly accurate image of this imaginary universe of perfect competition or perfect equality of opportunity, a world without inertia, without accumulation, without heredity or acquired properties, in which every moment is perfectly independent of the previous one, every soldier has a marshal’s baton in his knapsack, and every prize can be attained, instantaneously, by everyone, so that at each moment anyone can become anything. Capital, which, in its objectified or embodied forms, takes time to accumulate and which, as a potential capacity to produce profits and to reproduce itself in identical or expanded form, contains a tendency to persist in its being, is a force inscribed in the objectivity of things so that everything is not equally possible or impossible. And the structure of the distribution of the different types and subtypes of capital at a given moment in time represents the immanent structure of the social world, i.e. , the set of constraints, inscribed in the very reality of that world, which govern its functioning in a durable way, determining the chances of success for practices.
Bourdieu is clear in his writing that he does not intend this to be taken as unsubstantiated theoretical posture. Rather, it is a theory he has developed through his empirical research. Obviously, it is also informed by many other significant Western theorists, including Kant and Marx. There is something slightly tautological about the way he defines his terms: if capital is posited to explain all social structure, then any social structure may be explained according to a distribution of capital. This leads Bourdieu to theorize about many forms of capital less obvious than wealth, such as the symbolic capital, like academic degrees.
The costs of such a theory is that it demands that one begin the difficult task of enumerate different forms of capital and, importantly, the ways in which some forms of capital can be converted into others. It is a framework which, in principle, could be used to adequately explain social reality in a properly scientific way, as opposed to other frameworks that seem more intended to maintain the motivation of a political agenda or academic discipline. Indeed there is something “interdisciplinary” about the very proposal to address symbolic and economic power in a way that deals responsibly with their commensurability.
So it has to be posited simultaneously that economic capital is at the root of all the other types of capital and that these transformed, disguised forms of economic capital, never entirely reducible to that definition, produce their most specific effects only to the extent that they conceal (not least from their possessors) the fact that economic capital is at their root, in other words – but only in the last analysis – at the root of their effects. The real logic of the functioning of capital, the conversions from one type to another, and the law of conservation which governs them cannot be understood unless two opposing but equally partial views are superseded: on the one hand, economism, which, on the grounds that every type of capital is reducible in the last analysis to economic capital, ignores what makes the specific efficacy of the other types of capital, and on the other hand, semiologism (nowadays represented by structuralism, symbolic interactionism, or ethnomethodology), which reduces social exchanges to phenomena of communication and ignores the brutal fact of universal reducibility to economics.
[I must comment that after years in an academic environment where sincere intellectual effort seemed effectively boobytrapped by disciplinary trip wires around ethnomethodology, quantification, and so on, this Bourdieusian perspective continues to provide me fresh hope. I’ve written here before about Bourdieu’s Science of Science and Reflexivity (2004), which was a wake up call for me that led to my writing this paper. That has been my main entrypoint into Bourdieu’s thought until now. The essay I’m quoting from now was published at least fifteen years prior and by its 34k citations appears to be a classic. Much of what’s written here will no doubt come across as obvious to the sophisticated reader. It is a symptom of a perhaps haphazard education that leads me to write about it now as if I’ve discovered it; indeed, the personal discovery is genuine for me, and though it is not a particularly old work, reading it and thinking it over carefully does untangle some of the knots in my thinking as I try to understand society and my role in it. Perhaps some of that relief can be shared through writing here.]
Naturally, Bourdieu’s account of capital is more nuanced and harder to measure than an economist’s. But it does not preclude an analysis of economic capital such as Piketty‘s. Indeed, much of the economist’s discussion of human capital, especially technological skill, and its relationship to wages can be mapped to a discussion of a specific form of cultural capital and how it can be converted into economic capital. A helpful aspect of this shift is that it allows one to conceptualize the effects of class, gender, and racial privilege in the transmission of technical skills. Cultural capital is, explicitly in Bourdieu’s account, labor intensive to transmit and often done so informally. Cultural tendencies to transmit this kind of capital preferentially to men instead of women in the family home become a viable explanation for the gender cap in the tech industry. While this is perhaps not a novel explanation, it is a significant one and Bourdieu’s theory helps us formulate it in a specific and testable way that transcends, as he says, both economism and semiologism, which seems productive when one is discussing society in a serious way.
One could also use a Bourdieusian framework to understand innovation spillover effects, as economists like to discuss, or the rise of Silicon Valley’s “Regional Advantage” (Saxenian, 1996), to take a specific case. One of Saxenian’s arguments (as I gloss it) is that Silicon Valley was more economically effective as a region than Route 128 in Massachusetts because the influx of engineers experimenting with new business models and reinvesting their profits into other new technology industries created a confluence of relevant cultural capital (technical skill) and economic capital (venture capital) that allowed the economic capital to be deployed more effectively. In other words, it wasn’t that the engineers in Silicon Valley were better engineers than the engineers in Route 128; it was that the economic capital was being deployed in a way that was less informed by technical knowledge. [Incidentally, if this argument is correct, then in some ways it undermines an argument put forward recently for setting up a “cyber workforce incubator” for the Federal Government in the Bay Area based on the idea that it’s necessary to tap into the labor pool there. If what makes Silicon Valley is smart capital rather than smart engineers, then that explains why there are so many engineers there (they are following the money) but also suggests that the price of technical labor there may be inflated. Engineers elsewhere may be just as good at being part of a cyber workforce. Which is just to say that when Bourdieusian theory is taken seriously, it can have practical policy implications.]
One must imagine, when considering society thus, that one could in principle map out the whole of society and the distribution of capitals within it. I believe Bourdieu does something like this in Distinction (1979), which I haven’t read–it is sadly referred to in the United States as the kind of book that is too dense to read. This is too bad.
But I was going to talk about…
2. Democracy
There are at least two great moments in history when democracy flourished. They have something in common.
One is Ancient Greece. The account of the polis in Hannah Arendt’s The Human Condition (1, cf (2 3) makes the familiar point that the citizens of the Ancient Greek city-state were masters of economically independent households. It was precisely the independence of politics (polis – city) from household economic affairs (oikos – house) that defined political life. Owning capital, in this case land and maybe slaves, was a condition for democratic participation. The democracy, such as it was, was the political unity of otherwise free capital holders.
The other historical moment is the rise of the mercantile class and the emergence of the democratic public sphere, as detailed by Habermas. If the public sphere Habermas described (and to some extent idealized) has been critiqued as being “bourgeois masculinist” (Fraser), that critique is telling. The bourgeoisie were precisely those who were owners of newly activated forms of economic capital–ships, mechanizing technologies, and the like.
If we can look at the public sphere in its original form realistically through the disillusionment of criticism, the need for rational discourse among capital holders was strategically necessary for the bourgeoisie to make strategic decisions about how to collectively allocate their economic capital. The Viewed through the objective lens of information processing and pure strategy, the public sphere was an effective means of economic coordination that complemented the rise of the Weberian bureaucracy, which provided a predictable state and also created new demand for legal professionals and the early information workers: clerks and scriveners and such.
The diversity of professions necessary for the functioning of the modern mercantile state created a diversity of forms of cultural capital that could be exchanged for economic capital. Hence, capital diffused from its concentration in the aristocracy into the hands of the widening class of the bourgeoisie.
Neither the Ancient Greek nor the mercantile democracies were particularly inclusive. Perhaps there is no historical precedent for a fully inclusive democracy. Rather, there is precedent for egalitarian alliances of capital holders in cases where that capital is broadly enough distributed to constitute citizenship as an economic class. Moreover, I must insert here that the Bourdieusian model suggests that citizenship could extend through the diffusion of non-economic forms of capital as well. For example, membership in the clergy was a form of capital taken on by some of the gentry; this came, presumably, with symbolic and social capital. The public sphere creates opportunities for the public socialite that were distinct from the opportunities of the courtier or courtesan. And so on.
However exclusive these democracies were, Fraser’s account of subaltern publics and counterpublics is of course very significant. What about the early workers and womens movements? Arguably these too can be understood in Bourdieusian terms. There were other forms of (social and cultural, if not economic) capital that workers and women in particular had available that provided the basis for their shared political interest and political participation.
What I’m suggesting is that:
- Historically, the democratic impulse has been about uniting the interests of freeholders of capital.
- A Bourdieusian understanding of capital allows us to maintain this (analytically helpful) understanding of democracy while also acknowledging the complexity of social structure, through the many forms of capital
- That the complexity of society through the proliferation of forms of capital is one of, if not the, main mechanism of expanding effective citizenship, which is still conditioned on capital ownership even though we like to pretend it’s not.
Which leads me to my last point, which is about…
3. Oligarchy
If a democracy is a political unity of many different capital holders, what then is oligarchy in contrast?
Oligarchy is rule of the few, especially the rich few.
We know, through Bourdieu, that there are many ways to be rich (not just economic ways). Nevertheless, capital (in its many forms) is very unevenly distributed, which accounts for social structure.
To some extent, it is unrealistic to expect the flattening of this distribution. Society is accumulated history and there has been a lot of history and most of it has been brutally unkind.
However, there have been times when capital (in its many forms) has diffused because of the terms of capital exchange, broadly speaking. The functional separation of different professions was one way in which capital was fragmented into many differently exchangeable forms of cultural, social, and economic capitals. A more complex society is therefore a more democratic one, because of the diversity of forms of capital required to manage it. [I suspect there’s a technically specific way to make this point but don’t know how to do it yet.]
There are some consequences of this.
- Inequality in the sense of a very skewed distribution of capital and especially economic capital does in fact undermine democracy. You can’t really be a citizen unless you have enough capital to be able to act (use your labor) in ways that are not fully determined by economic survival. And of course this is not all or nothing; quantity of capital and relative capital do matter even beyond a minimum threshold.
- The second is that (1) can’t be the end of the story. Rather, to judge if the capital distribution of e.g. a nation can sustain a democracy, you need to account for many kinds of capital, not just economic capital, and see how these are distribute and exchanged. In other words, it’s necessary to look at the political economy broadly speaking. (But, I think, it’s helpful to do so in terms of ‘forms of capital’.)
One example, which I just learned recently, is this. In the United States, we have an independent judiciary, a third branch of government. This is different from other countries that are allegedly oligarchies, notably Russia but also Rhode Island before 2004. One could ask: is this Separation of Powers important for democracy? The answer is intuitively “yes”, and though I’m sure very smart things have been written to answer the question “why”, I haven’t read them, because I’ve been too busy blogging….
Instead, I have an answer for you based on the preceding argument. It was a new idea for me. It was this: What separation of powers does is its constructs a form of cultural capital associated with professional lawyers which is less exchangeable for economic and other forms of capital than in places where non-independence of the judiciary leads to more regular bribery, graft, and preferential treatment. Because it mediates economic exchanges, this has a massively distortative effect on the ability of economic capital to bulldoze other forms of capital, and the accompanying social structures (and social strictures) that bind it. It also creates a new professional class who can own this kind of capital and thereby accomplish citizenship.
Coda
In this blog post, I’ve suggested that not everybody who, for example, legally has suffrage in nominally democratic state is, in an effective sense, a citizen. Only capital owners can be citizens.
This is not intended in any way to be a normative statement about who should or should not be a citizen. Rather, it is a descriptive statement about how power is distributed in nominal democracies. To be an effective citizen, you need to have some kind of surplus of social power; capital the objectification of that social power.
The project of expanding democracy, if it is to be taken seriously, needs to be understood as the project of expanding capital ownership. This can include the redistribution of economic capital. It can also changing institutions that ground cultural and social capitals in ways that distribute other forms of capital more widely. Diversifying professional roles is a way of doing this.
Nothing I’ve written here is groundbreaking, for sure. It is for me a clearer way to think about these issues than I have had before.



![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002)
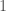

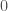
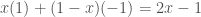

![E[2x+1]](https://s0.wp.com/latex.php?latex=E%5B2x%2B1%5D&bg=fff&fg=444444&s=0&c=20201002)

 (that is, a value
(that is, a value 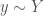 . Upon observation of
. Upon observation of 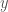 , they can make their judgments based on an improved subjective expectation of the unknown variable,
, they can make their judgments based on an improved subjective expectation of the unknown variable,  . We assumed that the agent was a Bayesian reasoner and so capable of internalizing evidence according to Bayes rule, hence they are able to compute:
. We assumed that the agent was a Bayesian reasoner and so capable of internalizing evidence according to Bayes rule, hence they are able to compute:
 . This is quite a strong assumption, as it implies that the agent knows truly how Y covaries with X, allowing them to “decode” the message
. This is quite a strong assumption, as it implies that the agent knows truly how Y covaries with X, allowing them to “decode” the message 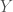 (observable symptoms) than the consumer (patient) did. In the case of companies that use data science, the idea is that some combination of data and science gives the company an edge in knowing the true value of some uncertain property than its competitors.
(observable symptoms) than the consumer (patient) did. In the case of companies that use data science, the idea is that some combination of data and science gives the company an edge in knowing the true value of some uncertain property than its competitors.
 . This is a difficult demand. A lot of computational statistics has to do with the difficulty of tractably estimating the likelihood function, let alone computing it perfectly.
. This is a difficult demand. A lot of computational statistics has to do with the difficulty of tractably estimating the likelihood function, let alone computing it perfectly. (that is, sampled from random variable
(that is, sampled from random variable 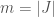 products. We’ll denote with
products. We’ll denote with  the utility awarded to the consumer for the consumption of product
the utility awarded to the consumer for the consumption of product 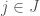 .
.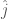 based on their knowledge of the underlying probability distribution
based on their knowledge of the underlying probability distribution ![\hat j = arg \max_{j \in J} E[X_j]](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002)
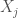 is the probability distribution over
is the probability distribution over 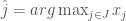
![E[X_j]](https://s0.wp.com/latex.php?latex=E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002) , whereas the higher the number of products
, whereas the higher the number of products 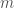 the more
the more  will approach the maximum value of
will approach the maximum value of 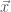 , they can choose:
, they can choose:![\hat j = arg \max_{j \in J} E[X_j \vert y] =](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j+%5Cvert+y%5D+%3D&bg=fff&fg=444444&s=0&c=20201002)
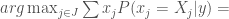

 dominates the prior
dominates the prior  and the condition of the consumer improves.
and the condition of the consumer improves. that is the special information that the producer has. Knowledge of how evidence (a search query, a description of symptoms, etc.) are caused by underlying desire or need is the expertise the consumers are seeking out. This begins to tie the economics of information to theories of statistical information.
that is the special information that the producer has. Knowledge of how evidence (a search query, a description of symptoms, etc.) are caused by underlying desire or need is the expertise the consumers are seeking out. This begins to tie the economics of information to theories of statistical information. , where the number of customers is
, where the number of customers is  . Let’s say each has a willingness to pay for the firm’s product,
. Let’s say each has a willingness to pay for the firm’s product, 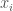 . Their willingness to pay is sampled from an underlying probability distribution
. Their willingness to pay is sampled from an underlying probability distribution 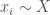 .
. to everybody. Each customer will buy the product if
to everybody. Each customer will buy the product if  , and otherwise won’t. Each customer that buys the product contributes
, and otherwise won’t. Each customer that buys the product contributes 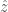 according to the following function:
according to the following function:![\hat z = arg \max_z E[\sum_i z [x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+E%5B%5Csum_i+z+%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
![\hat z = arg \max_z \sum_i E[z [x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+%5Csum_i+E%5Bz+%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
![\hat z = arg \max_z \sum_i z E[[x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+%5Csum_i+z+E%5B%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
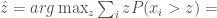

![[x_i > z]](https://s0.wp.com/latex.php?latex=%5Bx_i+%3E+z%5D+&bg=fff&fg=444444&s=0&c=20201002) is a function with value 1 if
is a function with value 1 if  . These customers get 0 utility from the product and pay nothing to the producer despite their willingness to pay.
. These customers get 0 utility from the product and pay nothing to the producer despite their willingness to pay. accordingly. The producer can price
accordingly. The producer can price  , effectively capturing the entire demand
, effectively capturing the entire demand  as producer surplus, while reducing all consumer surplus and deadweight loss to zero.
as producer surplus, while reducing all consumer surplus and deadweight loss to zero. , having their personal willingness to pay revealed to the firm means that they lose their consumer surplus. Their welfare is reduced.
, having their personal willingness to pay revealed to the firm means that they lose their consumer surplus. Their welfare is reduced. , these discover that they now can afford the product as it is priced close to their willingness to pay.
, these discover that they now can afford the product as it is priced close to their willingness to pay. that is a clue to their true
that is a clue to their true  and will choose each
and will choose each ![z_i = arg \max_z E[z [P(x_i > z \vert y_i)]]](https://s0.wp.com/latex.php?latex=z_i+%3D+arg+%5Cmax_z+E%5Bz+%5BP%28x_i+%3E+z+%5Cvert+y_i%29%5D%5D&bg=fff&fg=444444&s=0&c=20201002)
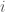 and gets utility
and gets utility ![E[X]](https://s0.wp.com/latex.php?latex=E%5BX%5D&bg=fff&fg=444444&s=0&c=20201002) . The expected welfare of each applicant is their utility from getting the job (let’s say it’s
. The expected welfare of each applicant is their utility from getting the job (let’s say it’s 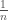 .
. . Let
. Let  . Then the utility for applicant
. Then the utility for applicant 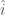 is
is ![(\max x_i) - E[X]](https://s0.wp.com/latex.php?latex=%28%5Cmax+x_i%29+-+E%5BX%5D&bg=fff&fg=444444&s=0&c=20201002) that accrues to the totally informed employer. One wonders if a “safety net” were to be provided those who have lost out in this change; if it could be, it would presumably be funded from this surplus. If the surplus were entirely taxed and redistributed among the applicants who did not get the job, it would provide each rejected applicant with
that accrues to the totally informed employer. One wonders if a “safety net” were to be provided those who have lost out in this change; if it could be, it would presumably be funded from this surplus. If the surplus were entirely taxed and redistributed among the applicants who did not get the job, it would provide each rejected applicant with ![\frac{(\max x_i) - E[X]}{n-1}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%28%5Cmax+x_i%29+-+E%5BX%5D%7D%7Bn-1%7D&bg=fff&fg=444444&s=0&c=20201002) utility. Adding a little complexity to the model we could be more precise by computing the wage paid to the worker and identify whether redistribution could potentially recover the losses of the weaker applicants.
utility. Adding a little complexity to the model we could be more precise by computing the wage paid to the worker and identify whether redistribution could potentially recover the losses of the weaker applicants.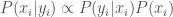
![arg\max E[P(x_i \vert y_i)] =](https://s0.wp.com/latex.php?latex=arg%5Cmax+E%5BP%28x_i+%5Cvert+y_i%29%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)


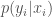 will overcome the prior expectations. It would be nice to be able to capture the impact of this additional information in a general way. One would think that providing limited information about applicants to the employer would result in an intermediate outcome. Under reasonable assumptions, more qualified applicants would be more likely to be hired and the employer would accrue more value from the work.
will overcome the prior expectations. It would be nice to be able to capture the impact of this additional information in a general way. One would think that providing limited information about applicants to the employer would result in an intermediate outcome. Under reasonable assumptions, more qualified applicants would be more likely to be hired and the employer would accrue more value from the work.
