
LLMs as computation
LLMs are now”doing” a lot of technical system design and are the object of a great deal of computer science research. However, I’ve surprised by much of the research that crosses my way (admittedly likely not a great sample) treats LLMs as a general form of intelligence without treating it as a form of computation. I expect that some combination of theory of computation (such as algorithmic information theory) and structural economics is needed to get a rigorous handle on the AI economy. This blog post contains some notes toward this end.
As we all know, an LLM is a collection of neural network weights, trained on a massive amount of information, which consumes tokens and emits predicted next tokens. Simplifying a bit, we can model an LLM as a machine that, given a string of tokens, emits a string of tokens.
Let be the set of tokens, be the space of token strings of any length. Perhaps an LLM is a function:
Really, this is LLM “inference”. I’m omitting the inherent stochasticity of LLMs — more realistically, would be a conditional probability distribution. But leave that aside for now.
Assuming that can consume as input any string, and in principle produce as output any string, what we have here is a class of “universal programming language”, another formal mathematical construct. “universal programming languages” appear in algorithmic information theory.
The simplest form of “universal programming language” is the print function. It repeats as output anything put into it. People (including myself) once joked that LLMs are glorified autocomplete; they clearly do more than this. The weights must matter.
Really, LLMs are parameterized functions — the parameters are weights of the neural network.
The weights are a compression of a great deal of training data . Let’s assume training has converted this data to a set of weights . We can refer to this foundation model as or .
What else can you do with these models? You can provide them ‘context’ — additional strings as input. You can fine-tune them on more data. And you can use them for ‘reasoning’ by chaining inputs and outputs.
- Context: allow multiple string inputs
- Fine-tuning: — further compresses additional data into the model weights
- Reasoning: applies the model recursively times
So if we want to look at the data and computation pipeline of an LLM based system, we get something like:
I.e., we train on a base data set and several fine-tuning data sets, pick context and an input, and run inference some number of times. Each of these steps has a cost function, and we can then computer the average costs of solving various sets of problems given the available data, and other statistics. This then can be used to design the most efficient pipelines and markets.
I would be interested in hearing from anybody about whether and how this faithfully captures the essentials of LLMs as a form of computation. This is my ‘mental model’. I have left out tool use and interactivity, among other things, but those can be added in easily.
Why am I writing this? Because I think that clearly articulating the formal properties of LLMs brings a number of issues to light.
First, it foregrounds the importance of training data. Famously, the transformer architecture is very general, and early innovation in LLMs was largely about scaling it up to greater amounts of data. If we are interested in the behavior of LLMs, the training data and the training algorithm are the parts that are not “black boxes” to the model creators.
As we look at the future of LLMs in the economy, we will be looking at the results of differential access to data, as well as what data is commonly available. This shares a lot of patterns with previous iterations of concerns over “big data”, but this is obscured today because of the charisma of the models themselves.
Second, it makes explicit how information can flow and transform into a system output. The information comes first from training and fine-tuning data, then from context, then from system input. If the training and inference algorithms are general enough, none of the information relevant to a specific task comes from those parts of the system. Those algorithms are ‘general computing’.
Third, it breaks up training and inference. While training and inference are not so different in terms of information flow, they are in practice quite different because of their physical and economic costs. Currently, training is more expensive than inference. So, we see a race to, expensively, train general models with more and more data, so that less and less data is needed in context at inference time, and fewer steps are needed during reasoning. A structural model that distinguishes these can discriminate between several investment hypotheses in this space.
Fourth, by revealing LLMs as a form of general data processing and computation, it deflates (in what I think is a good and necessary way) the tendency to see ‘model evaluations’ as the best way to enforce AI accuracy, fairness, privacy, and so on. My general frustration with the model evaluation literature is that LLMs are that if they are a flavor of universal programming language by design, then there will, by definition, always be a jailbreak or a hallucination available to them. A lot of work on ‘guardrails’ at the model level seems to be about making certain kinds of outputs more difficult or expensive to get. As we’ve seen, there will be open models, and they will get fine-tuned by hobbyists and others to get around the guardrails, and so that’s not going to be an effective strategy long term.
This means that a lot of AI product design and regulation seems to be about shifting around the cost functions for achieving certain kinds of outputs with certain data. If ‘bad’ behaviors are expensive, and ‘good’ behaviors are cheap, then we have, in a sense, succeeded. But this means that the underlying economics must be part of the analysis for it to have forward-going relevance and replicability. Today’s model capabilities are a function of whatever the latest investment — at the training and inference level, as well as the data flow of context and inputs, which may go back into training — is. The entire pipeline produces ‘the intelligence’, and it does so at physical and economic cost. Computer science research, per se, with its focus on the currently available digital artifacts, is not going to achieve lasting results unless it expands its purview to these broader systems and considerations. Likewise, evaluations of models alone will not provide us the reliable theoretical knowledge needed to steer public policy. We must take into account production costs and data pipelines.
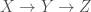 , then
, then  , where here
, where here 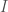 stands for mutual information. Mutual information is a measure of how much two random variables carry information about each other. If $I(X,Y) = 0$, that means the variables are independent. $I(X,Y) \geq 0$ always–that’s just a mathematical fact about how it’s defined.
stands for mutual information. Mutual information is a measure of how much two random variables carry information about each other. If $I(X,Y) = 0$, that means the variables are independent. $I(X,Y) \geq 0$ always–that’s just a mathematical fact about how it’s defined.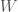 and there’s am organism, or a person, or a sociotechnical organization within it,
and there’s am organism, or a person, or a sociotechnical organization within it, 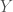 . The world is big and complex, which implies that it has a lot of informational entropy,
. The world is big and complex, which implies that it has a lot of informational entropy, 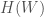 . Through whatever sensory apparatus is available to
. Through whatever sensory apparatus is available to  . This in turn bounds the mutual information between the organism and the world:
. This in turn bounds the mutual information between the organism and the world: 
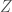 depend only on its internal state. It is an agent, reacting to its environment. Well whatever these actions are, they can only be so calibrated to the world as the agent had capacity to absorb the world’s information. I.e.,
depend only on its internal state. It is an agent, reacting to its environment. Well whatever these actions are, they can only be so calibrated to the world as the agent had capacity to absorb the world’s information. I.e.,  . The implication is that the more limited the mental capacity of the organism, the more its actions will be approximately independent of the state of the world that precedes it.
. The implication is that the more limited the mental capacity of the organism, the more its actions will be approximately independent of the state of the world that precedes it. 