
Information flow in economics
We have formalized three different cases of information economics:
- Information about supply quality. For example, Posner’s case of an employer reviewing job applicants.
- Information about consumer willingness-to-pay. As in the case of a firm engaged in personalized price discrimination.
- Expertise. Where the service being sold involves special insight that the consumer does not have.
What we discovered is that each of these cases has, to some extent, a common form. That form is this:
There is a random variable of interest, 


In the extreme cases, the agent at the focus of the economic model could act with extreme ignorance of
We also considered the possibility that the agent has access to partial information about 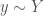


However, this depends on two very important assumptions.
The first is that the agent knows the distribution
The second important assumption is that the agent knows the likelihood function 
It may be best to think of access and usage of the likelihood function as a rare capability. Indeed, in our model of expertise, the assumption was that the service provider (think doctor) knew more about the relationship between 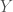
What we are discovering is that it’s not just the availability of
This incidentally ties in with a point which we have perhaps glossed over too quickly in the present discussion, which is what is information, really? This may seem like a distraction in a discussion about economics but it is a question that’s come up in my own idiosyncratic “disciplinary” formation. One of the best intuitive definitions of information is provided by philosopher Fred Dretske (1981; 1983). Made a presentation of Fred Dretske’s view on information and its relationship to epistemological skepticism and Shannon information theory; you can find this presentation here. But for present purposes I want to call attention to his definition of what it means for a message to carry information, which is:
[A] message carries the information that X is a dingbat, say, if and only if one could learn (come to know) that X is a dingbat from the message.
When I say that one could learn that X was a dingbat from the message, I mean, simply, that the message has whatever reliable connection with dingbats is required to enable a suitably equipped, but otherwise ignorant receiver, to learn from it that X is a dingbat.
This formulation is worth mentioning because it supplies a kind of philosophical validation for our Bayesian formulation of information flow in the economy. We are modeling situations where Y is a signal that is reliably connected with X such that instantiations of Y carry information about the value of the X. We might express this in terms of conditional entropy:

While this is sufficient for Y to carry information about X, it is not sufficient for any observer of Y to consequently know X. An important part of Dretske's definition is that the receiver must be suitably equipped to make the connection.
In our models, the “suitably equipped” condition is represented as the ability to compute the Bayesian update using a realistic likelihood function 
References
Dretske, F. I. (1983). The epistemology of belief. Synthese, 55(1), 3-19.
Dretske, F. (1981). Knowledge and the Flow of Information.
