
“The Microeconomics of Complex Economies”
I’m dipping into The microeconomics of complex economies: Evolutionary, institutional, neoclassical, and complexity perspectives, by Elsner, Heinrich, and Schwardt, all professors at the University of Bremen.
It is a textbook, as one would teach a class from. It is interesting because it is self-consciously written as a break from neoclassical microeconomics. According to the authors, this break had been a long time coming but the last straw was the 2008 financial crisis. This at last, they claim, showed that neoclassical faith in market equilibrium was leaving something important out.
Meanwhile, “heterodox” economics has been maturing for some time in the economics blogosphere, while complex systems people have been interested in economics since the emergence of the field. What Elsner, Heinrich, and Schwardt appear to be doing with this textbook is providing a template for an undergraduate level course on the subject, legitimizing it as a discipline. They are not alone. They cite Bowles’s Microeconomics as worthy competition.
I have not yet read the chapter of the Elsner, Heinirch, and Schwardt book that covers philosophy of science and its relationship to the validity of economics. It looks from a glance at it very well done. But I wanted to note my preliminary opinion on the matter given my recent interest in Shapiro and Varian‘s information economics and their claim to be describing ‘laws of economics’ that provide a reliable guide to business strategy.
In brief, I think Shapiro and Varian are right: they do outline laws of economics that provide a reliable guide to business strategy. This is in fact what neoclassical economics is good for.
What neoclassical economics is not always great at is predicting aggregate market behavior in a complex world. It’s not clear if any theory could ever be good at predicting aggregate market behavior in a complex world. It is likely that if there were one, it would be quickly gamed by investors in a way that would render it invalid.
Given vast information asymmetries it seems the best one could hope for is a theory of the market being able to assimilate the available information and respond wisely. This is the Hayekian view, and it’s not mainstream. It suffers the difficulty that it is hard to empirically verify that a market has performed optimally given that no one actor, including the person attempting the verify Hayekian economic claims, has all the information to begin with. Meanwhile, it seems that there is no sound a priori reason to believe this is the case. Epstein and Axtell (1996) have some computational models where they test when agents capable of trade wind up in an equilibrium with market-clearing prices and in their models this happens under only very particular an unrealistic conditions.
That said, predicting aggregate market outcomes is a vastly different problem than providing strategic advice to businesses. This is the point where academic critiques of neoclassical economics miss the mark. Since phenomena concerning supply and demand, pricing and elasticity, competition and industrial organization, and so on are part of the lived reality of somebody working in industry, formalizations of these aspects of economic life can be tested and propagated by many more kinds of people than the phenomena of total market performance. The latter is actionable only for a very rare class of policy-maker or financier.
References
Bowles, S. (2009). Microeconomics: behavior, institutions, and evolution. Princeton University Press.
Elsner, W., Heinrich, T., & Schwardt, H. (2014). The microeconomics of complex economies: Evolutionary, institutional, neoclassical, and complexity perspectives. Academic Press.
Epstein, Joshua M., and Robert Axtell. Growing artificial societies: social science from the bottom up. Brookings Institution Press, 1996.
 (that is, sampled from random variable
(that is, sampled from random variable  , specifying the values it gets for the consumption of each of
, specifying the values it gets for the consumption of each of 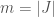 products. We’ll denote with
products. We’ll denote with  the utility awarded to the consumer for the consumption of product
the utility awarded to the consumer for the consumption of product 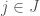 .
.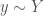 , which is correlated with
, which is correlated with 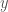 , and the producer’s job is to recommend to them
, and the producer’s job is to recommend to them 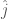 based on their knowledge of the underlying probability distribution
based on their knowledge of the underlying probability distribution ![\hat j = arg \max_{j \in J} E[X_j]](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002)
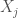 is the probability distribution over
is the probability distribution over 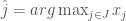
![E[X_j]](https://s0.wp.com/latex.php?latex=E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002) , whereas the higher the number of products
, whereas the higher the number of products 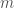 the more
the more  will approach the maximum value of
will approach the maximum value of 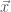 , they can choose:
, they can choose:![\hat j = arg \max_{j \in J} E[X_j \vert y] =](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j+%5Cvert+y%5D+%3D&bg=fff&fg=444444&s=0&c=20201002)
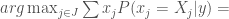

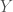 . What we can know in general is that the more informative is
. What we can know in general is that the more informative is  dominates the prior
dominates the prior  and the condition of the consumer improves.
and the condition of the consumer improves. that is the special information that the producer has. Knowledge of how evidence (a search query, a description of symptoms, etc.) are caused by underlying desire or need is the expertise the consumers are seeking out. This begins to tie the economics of information to theories of statistical information.
that is the special information that the producer has. Knowledge of how evidence (a search query, a description of symptoms, etc.) are caused by underlying desire or need is the expertise the consumers are seeking out. This begins to tie the economics of information to theories of statistical information. , where the number of customers is
, where the number of customers is  . Let’s say each has a willingness to pay for the firm’s product,
. Let’s say each has a willingness to pay for the firm’s product, 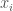 . Their willingness to pay is sampled from an underlying probability distribution
. Their willingness to pay is sampled from an underlying probability distribution 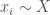 .
. to everybody. Each customer will buy the product if
to everybody. Each customer will buy the product if  , and otherwise won’t. Each customer that buys the product contributes
, and otherwise won’t. Each customer that buys the product contributes 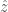 according to the following function:
according to the following function:![\hat z = arg \max_z E[\sum_i z [x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+E%5B%5Csum_i+z+%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
![\hat z = arg \max_z \sum_i E[z [x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+%5Csum_i+E%5Bz+%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
![\hat z = arg \max_z \sum_i z E[[x_i > z]] =](https://s0.wp.com/latex.php?latex=%5Chat+z+%3D+arg+%5Cmax_z+%5Csum_i+z+E%5B%5Bx_i+%3E+z%5D%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)
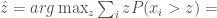

![[x_i > z]](https://s0.wp.com/latex.php?latex=%5Bx_i+%3E+z%5D+&bg=fff&fg=444444&s=0&c=20201002) is a function with value 1 if
is a function with value 1 if  . These customers get 0 utility from the product and pay nothing to the producer despite their willingness to pay.
. These customers get 0 utility from the product and pay nothing to the producer despite their willingness to pay. accordingly. The producer can price
accordingly. The producer can price  , effectively capturing the entire demand
, effectively capturing the entire demand  as producer surplus, while reducing all consumer surplus and deadweight loss to zero.
as producer surplus, while reducing all consumer surplus and deadweight loss to zero. , having their personal willingness to pay revealed to the firm means that they lose their consumer surplus. Their welfare is reduced.
, having their personal willingness to pay revealed to the firm means that they lose their consumer surplus. Their welfare is reduced. , these discover that they now can afford the product as it is priced close to their willingness to pay.
, these discover that they now can afford the product as it is priced close to their willingness to pay. that is a clue to their true
that is a clue to their true  and will choose each
and will choose each ![z_i = arg \max_z E[z [P(x_i > z \vert y_i)]]](https://s0.wp.com/latex.php?latex=z_i+%3D+arg+%5Cmax_z+E%5Bz+%5BP%28x_i+%3E+z+%5Cvert+y_i%29%5D%5D&bg=fff&fg=444444&s=0&c=20201002)
 all matter for the particular outcomes here, but intuitively one would expect the results of partial information to fall somewhere between the extremes of undifferentiated pricing and perfect price discrimination.
all matter for the particular outcomes here, but intuitively one would expect the results of partial information to fall somewhere between the extremes of undifferentiated pricing and perfect price discrimination.