Lately my academic research focus has been privacy engineering, the designing of information processing systems that preserve privacy of their users. I have been looking the problem particularly through the lens of Contextual Integrity, a theory of privacy developed by Helen Nissenbaum (2004, 2009). According to this theory, privacy is defined as appropriate information flow, where “appropriateness” is determined relative to social spheres (such as health, education, finance, etc.) that have evolved norms based on their purpose in society.
To my knowledge most existing scholarship on Contextual Integrity is comprised by applications of a heuristic process associated with Contextual Integrity that evaluates the privacy impact of new technology. In this process, one starts by identifying a social sphere (or context, but I will use the term social sphere as I think it’s less ambiguous) and its normative structure. For example, if one is evaluating the role of a new kind of education technology, one would identify the roles of the education sphere (teachers, students, guardians of students, administrators, etc.), the norms of information flow that hold in the sphere, and the disruptions to these norms the technology is likely to cause.
I’m coming at this from a slightly different direction. I have a background in enterprise software development, data science, and social theory. My concern is with the ways that technology is now part of the way social spheres are constituted. For technology to not just address existing norms but deal adequately with how it self-referentially changes how new norms develop, we need to focus on the parts of Contextual Integrity that have heretofore been in the background: the rich social and metaethical theory of how social spheres and their normative implications form.
Because the ultimate goal is the engineering of information systems, I am leaning towards mathematical modeling methods that trade well between social scientific inquiry and technical design. Mechanism design, in particular, is a powerful framework from mathematical economics that looks at how different kinds of structures change the outcomes for actors participating in “games” that involve strategy action and information flow. While mathematical economic modeling has been heavily critiqued over the years, for example on the basis that people do not act with the unbounded rationality such models can imply, these models can be a first step and valuable in a technical context especially as they establish the limits of a system’s manipulability by non-human actors such as AI. This latter standard makes this sort of model more relevant than it has ever been.
This is my roundabout way of beginning to investigate the fascinating field of privacy economics. I am a new entrant. So I found what looks like one of the earliest highly cited articles on the subject written by the prolific and venerable Richard Posner, “The Economics of Privacy”, from 1981.

Richard Posner, from Wikipedia
Wikipedia reminds me that Posner is politically conservative, though apparently he has changed his mind recently in support of gay marriage and, since the 2008 financial crisis, the laissez faire rational choice economic model that underlies his legal theory. As I have mainly learned about privacy scholarship from more left-wing sources, it was interesting reading an article that comes from a different perspective.
Posner’s opening position is that the most economically interesting aspect of privacy is the concealment of personal information, and that this is interesting mainly because privacy is bad for market efficiency. He raises examples of employers and employees searching for each other and potential spouses searching for each other. In these cases, “efficient sorting” is facilitated by perfect information on all sides. Privacy is foremost a way of hiding disqualifying information–such as criminal records–from potential business associates and spouses, leading to a market inefficiency. I do not know why Posner does not cite Akerlof (1970) on the “market for ‘lemons'” in this article, but it seems to me that this is the economic theory most reflective of this economic argument. The essential question raised by this line of argument is whether there’s any compelling reason why the market for employees should be any different from the market for used cars.
Posner raises and dismisses each objective he can find. One objection is that employers might heavily weight factors they should not, such as mental illness, gender, or homosexuality. He claims that there’s evidence to show that people are generally rational about these things and there’s no reason to think the market can’t make these decisions efficiently despite fear of bias. I assume this point has been hotly contested from the left since the article was written.
Posner then looks at the objection that privacy provides a kind of social insurance to those with “adverse personal characteristics” who would otherwise not be hired. He doesn’t like this argument because he sees it as allocating the costs of that person’s adverse qualities to a small group that has to work with that person, rather than spreading the cost very widely across society.
Whatever one thinks about whose interests Posner seems to side with and why, it is refreshing to read an article that at the very least establishes the trade offs around privacy somewhat clearly. Yes, discrimination of many kinds is economically inefficient. We can expect the best performing companies to have progressive hiring policies because that would allow them to find the best talent. That’s especially true if there are large social biases otherwise unfairly skewing hiring.
On the other hand, the whole idea of “efficient sorting” assumes a policy-making interest that I’m pretty sure logically cannot serve the interests of everyone so sorted. It implies a somewhat brutally Darwinist stratification of personnel. It’s quite possible that this is not healthy for an economy in the long term. On the other hand, in this article Posner seems open to other redistributive measures that would compensate for opportunities lost due to revelation of personal information.
There’s an empirical part of the paper in which Posner shows that percentage of black and Hispanic populations in a state are significantly correlated with existence of state level privacy statutes relating to credit, arrest, and employment history. He tries to spin this as an explanation for privacy statutes as the result of strongly organized black and Hispanic political organizations successfully continuing to lobby in their interest on top of existing anti-discrimination laws. I would say that the article does not provide enough evidence to strongly support this causal theory. It would be a stronger argument if the regression had taken into account the racial differences in credit, arrest, and employment state by state, rather than just assuming that this connection is so strong it supports this particular interpretation of the data. However, it is interesting that this variable ways more strongly correlated with the existence of privacy statutes than several other variables of interest. It was probably my own ignorance that made me not consider how strongly privacy statutes are part of a social justice agenda, broadly speaking. Considering that disparities in credit, arrest, and employment history could well be the result of other unjust biases, privacy winds up mitigating the anti-signal that these injustices have in the employment market. In other words, it’s not hard to get from Posner’s arguments to a pro-privacy position based of all things on market efficiency.
It would be nice to model that more explicitly, if it hasn’t been done yet already.
Posner is quite bullish on privacy tort, thinking that it is generally not so offensive from an economic perspective largely because it’s about preventing misinformation.
Overall, the paper is a valuable starting point for further study in economics of privacy. Posner’s economic lens swiftly and clearly puts the trade-offs around privacy statutes in the light. It’s impressively lucid work that surely bears directly on arguments about privacy and information processing systems today.
References
Akerlof, G. A. (1970). The market for” lemons”: Quality uncertainty and the market mechanism. The quarterly journal of economics, 488-500.
Nissenbaum, H. (2004). Privacy as contextual integrity. Wash. L. Rev., 79, 119.
Nissenbaum, H. (2009). Privacy in context: Technology, policy, and the integrity of social life. Stanford University Press.
Posner, R. A. (1981). The economics of privacy. The American economic review, 71(2), 405-409. (jstor)



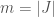

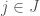
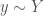
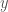
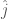
![\hat j = arg \max_{j \in J} E[X_j]](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002)
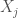
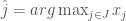
![E[X_j]](https://s0.wp.com/latex.php?latex=E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002)
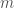

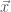
![\hat j = arg \max_{j \in J} E[X_j \vert y] =](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j+%5Cvert+y%5D+%3D&bg=fff&fg=444444&s=0&c=20201002)




 , where the number of candidates is
, where the number of candidates is  . Let’s say each is capable of performing at a certain level based on their background and aptitude,
. Let’s say each is capable of performing at a certain level based on their background and aptitude,  . Their aptitude is sampled from an underlying probability distribution
. Their aptitude is sampled from an underlying probability distribution 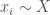 .
.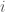 and gets utility
and gets utility ![E[X]](https://s0.wp.com/latex.php?latex=E%5BX%5D&bg=fff&fg=444444&s=0&c=20201002) . The expected welfare of each applicant is their utility from getting the job (let’s say it’s
. The expected welfare of each applicant is their utility from getting the job (let’s say it’s 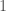 for simplicity) times their probability of being picked, which comes to
for simplicity) times their probability of being picked, which comes to 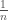 .
. . Let
. Let  . Then the utility for applicant
. Then the utility for applicant 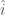 is
is 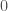 for the other applicants.
for the other applicants.![(\max x_i) - E[X]](https://s0.wp.com/latex.php?latex=%28%5Cmax+x_i%29+-+E%5BX%5D&bg=fff&fg=444444&s=0&c=20201002) that accrues to the totally informed employer. One wonders if a “safety net” were to be provided those who have lost out in this change; if it could be, it would presumably be funded from this surplus. If the surplus were entirely taxed and redistributed among the applicants who did not get the job, it would provide each rejected applicant with
that accrues to the totally informed employer. One wonders if a “safety net” were to be provided those who have lost out in this change; if it could be, it would presumably be funded from this surplus. If the surplus were entirely taxed and redistributed among the applicants who did not get the job, it would provide each rejected applicant with ![\frac{(\max x_i) - E[X]}{n-1}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%28%5Cmax+x_i%29+-+E%5BX%5D%7D%7Bn-1%7D&bg=fff&fg=444444&s=0&c=20201002) utility. Adding a little complexity to the model we could be more precise by computing the wage paid to the worker and identify whether redistribution could potentially recover the losses of the weaker applicants.
utility. Adding a little complexity to the model we could be more precise by computing the wage paid to the worker and identify whether redistribution could potentially recover the losses of the weaker applicants. which is reflective of their abilities. When the employer makes her decision, her expectation of the performance of each applicant is
which is reflective of their abilities. When the employer makes her decision, her expectation of the performance of each applicant is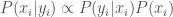
![arg\max E[P(x_i \vert y_i)] =](https://s0.wp.com/latex.php?latex=arg%5Cmax+E%5BP%28x_i+%5Cvert+y_i%29%5D+%3D+&bg=fff&fg=444444&s=0&c=20201002)


 matter a great deal to the outcome. But from the expanded form of the equation we can see that the more revealing
matter a great deal to the outcome. But from the expanded form of the equation we can see that the more revealing 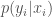 will overcome the prior expectations. It would be nice to be able to capture the impact of this additional information in a general way. One would think that providing limited information about applicants to the employer would result in an intermediate outcome. Under reasonable assumptions, more qualified applicants would be more likely to be hired and the employer would accrue more value from the work.
will overcome the prior expectations. It would be nice to be able to capture the impact of this additional information in a general way. One would think that providing limited information about applicants to the employer would result in an intermediate outcome. Under reasonable assumptions, more qualified applicants would be more likely to be hired and the employer would accrue more value from the work.