
The Data Processing Inequality and bounded rationality
I have long harbored the hunch that information theory, in the classic Shannon sense, and social theory are deeply linked. It has proven to be very difficult to find an audience for this point of view or an opportunity to work on it seriously. Shannon’s information theory is widely respected in engineering disciplines; many social theorists who are unfamiliar with it are loathe to admit that something from engineering should carry essential insights for their own field. Meanwhile, engineers are rarely interested in modeling social systems.
I’ve recently discovered an opportunity to work on this problem through my dissertation work, which is about privacy engineering. Privacy is a subtle social concept but also one that has been rigorously formalized. I’m working on formal privacy theory now and have been reminded of a theorem from information theory: the Data Processing Theorem. What strikes me about this theorem is that is captures an point that comes up again and again in social and political problems, though it’s a point that’s almost never addressed head on.
The Data Processing Inequality (DPI) states that for three random variables, X, Y, and Z, arranged in Markov Chain such that 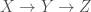

The implications of this for psychology, social theory, and artificial intelligence are I think rather profound. It provides a way of thinking about bounded rationality in a simple and generalizable way–something I’ve been struggling to figure out for a long time.
Suppose that there’s a big world out the, 
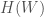


Now let’s suppose the actions that the organism takes, 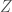

There are a lot of interesting implications of this for social theory. Here are a few cases that come to mind.
I've written quite a bit here (blog links) and here (arXiv) about Bostrom’s superintelligence argument and why I’m generally not concerned with the prospect of an artificial intelligence taking over the world. My argument is that there are limits to how much an algorithm can improve itself, and these limits put a stop to exponential intelligence explosions. I’ve been criticized on the grounds that I don’t specify what the limits are, and that if the limits are high enough then maybe relative superintelligence is possible. The Data Processing Inequality gives us another tool for estimating the bounds of an intelligence based on the range of physical states it can possibly be in. How calibrated can a hegemonic agent be to the complexity of the world? It depends on the capacity of that agent to absorb information about the world; that can be measured in information entropy.
A related case is a rendering of Scott’s Seeing Like a State arguments. Why is it that “high modernist” governments failed to successfully control society through scientific intervention? One reason is that the complexity of the system they were trying to manage vastly outsized the complexity of the centralized control mechanisms. Centralized control was very blunt, causing many social problems. Arguably, behavioral targeting and big data centers today equip controlling organizations with more informational capacity (more entropy), but they
still get it wrong sometimes, causing privacy violations, because they can’t model the entirety of the messy world we’re in.
The Data Processing Inequality is also helpful for explaining why the world is so messy. There are a lot of different agents in the world, and each one only has so much bandwidth for taking in information. This means that most agents are acting almost independently from each other. The guiding principle of society isn’t signal, it’s noise. That explains why there are so many disorganized heavy tail distributions in social phenomena.
Importantly, if we let the world at any time slice be informed by the actions of many agents acting nearly independently from each other in the slice before, then that increases the entropy of the world. This increases the challenge for any particular agent to develop an effective controlling strategy. For this reason, we would expect the world to get more out of control the more intelligence agents are on average. The popularity of the personal computer perhaps introduced a lot more entropy into the world, distributed in an agent-by-agent way. Moreover, powerful controlling data centers may increase the world’s entropy, rather than redtucing it. So even if, for example, Amazon were to try to take over the world, the existence of Baidu would be a major obstacle to its plans.
There are a lot of assumptions built into these informal arguments and I’m not wedded to any of them. But my point here is that information theory provides useful tools for thinking about agents in a complex world. There’s potential for using it for modeling sociotechnical systems and their limitations.
 (that is, sampled from random variable
(that is, sampled from random variable  , specifying the values it gets for the consumption of each of
, specifying the values it gets for the consumption of each of 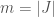 products. We’ll denote with
products. We’ll denote with  the utility awarded to the consumer for the consumption of product
the utility awarded to the consumer for the consumption of product 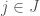 .
.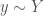 , which is correlated with
, which is correlated with 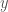 , and the producer’s job is to recommend to them
, and the producer’s job is to recommend to them 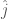 based on their knowledge of the underlying probability distribution
based on their knowledge of the underlying probability distribution ![\hat j = arg \max_{j \in J} E[X_j]](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002)
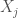 is the probability distribution over
is the probability distribution over 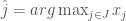
![E[X_j]](https://s0.wp.com/latex.php?latex=E%5BX_j%5D&bg=fff&fg=444444&s=0&c=20201002) , whereas the higher the number of products
, whereas the higher the number of products 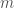 the more
the more  will approach the maximum value of
will approach the maximum value of 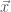 , they can choose:
, they can choose:![\hat j = arg \max_{j \in J} E[X_j \vert y] =](https://s0.wp.com/latex.php?latex=%5Chat+j+%3D+arg+%5Cmax_%7Bj+%5Cin+J%7D+E%5BX_j+%5Cvert+y%5D+%3D&bg=fff&fg=444444&s=0&c=20201002)
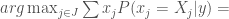

 dominates the prior
dominates the prior  and the condition of the consumer improves.
and the condition of the consumer improves. that is the special information that the producer has. Knowledge of how evidence (a search query, a description of symptoms, etc.) are caused by underlying desire or need is the expertise the consumers are seeking out. This begins to tie the economics of information to theories of statistical information.
that is the special information that the producer has. Knowledge of how evidence (a search query, a description of symptoms, etc.) are caused by underlying desire or need is the expertise the consumers are seeking out. This begins to tie the economics of information to theories of statistical information.