
Existentialism in Design: Comparison with “Friendly AI” research

Turing Test [xkcd]
I made a few references to Friendly AI research in my last post on Existentialism in Design. I positioned existentialism as an ethical perspective that contrasts with the perspective taken by the Friendly AI research community, among others. This prompted a response by a pseudonymous commenter (in a sadly condescending way, I must say) who linked me to a a post, “Complexity of Value” on what I suppose you might call the elite rationalist forum Arbital. I’ll take this as an invitation to elaborate on how I think existentialism offers an alternative to the Friendly AI perspective of ethics in technology, and particularly the ethics of artificial intelligence.
The first and most significant point of departure between my work on this subject and Friendly AI research is that I emphatically don’t believe the most productive way to approach the problem of ethics in AI is to consider the problem of how to program a benign Superintelligence. This is for reasons I’ve written up in “Don’t Fear the Reaper: Refuting Bostrom’s Superintelligence Argument”, which sums up arguments made in several blog posts about Nick Bostrom’s book on the subject. This post goes beyond the argument in the paper to address further objections I’ve heard from Friendly AI and X-risk enthusiasts.
What superintelligence gives researchers is a simplified problem. Rather than deal with many of the inconvenient contingencies of humanity’s technically mediated existence, superintelligence makes these irrelevant in comparison to the limiting case where technology not only mediates, but dominates. The question asked by Friendly AI researchers is how an omnipotent computer should be programmed so that it creates a utopia and not a dystopia. It is precisely because the computer is omnipotent that it is capable of producing a utopia and is in danger of creating a dystopia.
If you don’t think superintelligences are likely (perhaps because you think there are limits to the ability of algorithms to improve themselves autonomously), then you get a world that looks a lot more like the one we have now. In our world, artificial intelligence has been incrementally advancing for maybe a century now, starting with the foundations of computing in mathematical logic and electrical engineering. It proceeds through theoretical and engineering advances in fits and starts, often through the application of technology to solve particular problems, such as natural language processing, robotic control, and recommendation systems. This is the world of “weak AI”, as opposed to “strong AI”.
It is also a world where AI is not the great source of human bounty or human disaster. Rather, it is a form of economic capital with disparate effects throughout the total population of humanity. It can be a source of inspiring serendipity, banal frustration, and humor.
Let me be more specific, using the post that I was linked to. In it, Eliezer Yudkowsky posits that a (presumeably superintelligent) AI will be directed to achieve something, which he calls “value”. The post outlines a “Complexity of Value” thesis. Roughly, this means that the things that we want AI to do cannot be easily compressed into a brief description. For an AI to not be very bad, it will need to either contain a lot of information about what people really want (more than can be easily described) or collect that information as it runs.
That sounds reasonable to me. There’s plenty of good reasons to think that even a single person’s valuations are complex, hard to articulate, and contingent on their circumstances. The values appropriate for a world dominating supercomputer could well be at least as complex.
But so what? Yudkowsky argues that this thesis, if true, has implications for other theoretical issues in superintelligence theory. But does it address any practical questions of artificial intelligence problem solving or design? That it is difficult to mathematically specify all of values or normativity, and that to attempt to do so one would need to have a lot of data about humanity in its particularity, is a point that has been apparent to ethical philosophy for a long time. It’s a surprise or perhaps disappointment only to those who must mathematize everything. Articulating this point in terms of Kolmogorov complexity does not particularly add to the insight so much as translate it into an idiom used by particular researchers.
Where am I departing from this with “Existentialism in Design”?
Rather than treat “value” as a wholly abstract metasyntactic variable representing the goals of a superintelligent, omniscient machine, I’m approaching the problem more practically. First, I’m limiting myself to big sociotechnical complexes wherein a large number of people have some portion of their interactions mediated by digital networks and data centers and, why not, smartphones and even the imminent dystopia of IoT devices. This may be setting my work up for obsolescence, but it also grounds the work in potential action. Since these practical problems rely on much of the same mathematical apparatus as the more far-reaching problems, there is a chance that a fundamental theorem may arise from even this applied work.
That restriction on hardware may seem banal; but it’s a particular philosophical question that I am interested in. The motivation for considering existentialist ethics in particular is that it suggests new kinds of problems that are relevant to ethics but which have not been considered carefully or solved.
As I outlined in a previous post, many ethical positions are framed either in terms of consequentialism, evaluating the utility of a variety of outcomes, or deontology, concerned with the consistency of behavior with more or less objectively construed duties. Consequentialism is attractive to superintelligence theorists because they imagine their AI’s to have to ability to cause any consequence. The critical question is how to give it a specification the leads to the best or adequate consequences for humanity. This is a hard problem, under their assumptions.
Deontology is, as far as I can tell, less interesting to superintelligence theorists. This may be because deontology tends to be an ethics of human behavior, and for superintelligence theorists human behavior is rendered virtually insignificant by superintelligent agency. But deontology is attractive as an ethics precisely because it is relevant to people’s actions. It is intended as a way of prescribing duties to a person like you and me.
With Existentialism in Design (a term I may go back and change in all these posts at some point; I’m not sure I love the phrase), I am trying to do something different.
I am trying to propose an agenda for creating a more specific goal function for a limited but still broad-reaching AI, assigning something to its ‘value’ variable, if you will. Because the power of the AI to bring about consequences is limited, its potential for success and failure is also more limited. Catastrophic and utopian outcomes are not particularly relevant; performance can be evaluated in a much more pedestrian way.
Moreover, the valuations internalized by the AI are not to be done in a directly consequentialist way. I have suggested that an AI could be programmed to maximize the meaningfulness of its choices for its users. This is introducing a new variable, one that is more semantically loaded than “value”, though perhaps just as complex and amorphous.
Particular to this variable, “meaningfulness”, is that it is a feature of the subjective experience of the user, or human interacting with the system. It is only secondarily or derivatively an objective state of the world that can be evaluated for utility. To unpack in into a technical specification, we will require a model (perhaps a provisional one) of the human condition and what makes life meaningful. This very well may include such things as the autonomy, or the ability to make one’s own choices.
I can anticipate some objections along the lines that what I am proposing still looks like a special case of more general AI ethics research. Is what I’m proposing really fundamentally any different than a consequentialist approach?
I will punt on this for now. I’m not sure of the answer, to be honest. I could see it going one of two different ways.
The first is that yes, what I’m proposing can be thought of as a narrow special case of a more broadly consequentialist approach to AI design. However, I would argue that the specificity matters because of the potency of existentialist moral theory. The project of specify the latter as a kind of utility function suitable for programming into an AI is in itself a difficult and interesting problem without it necessarily overturning the foundations of AI theory itself. It is worth pursuing at the very least as an exercise and beyond that as an ethical intervention.
The second case is that there may be something particular about existentialism that makes encoding it different from encoding a consequentialist utility function. I suspect, but leave to be shown, that this is the case. Why? Because existentialism (which I haven’t yet gone into much detail describing) is largely a philosophy about how we (individually, as beings thrown into existence) come to have values in the first place and what we do when those values or the absurdity of circumstances lead us to despair. Existentialism is really a kind of phenomenological metaethics in its own right, one that is quite fluid and resists encapsulation in a utility calculus. Most existentialists would argue that at the point where one externalizes one’s values as a utility function as opposed to living as them and through them, one has lost something precious. The kinds of things that existentialism derives ethical imperatives from, such as the relationship between one’s facticity and transcendence, or one’s will to grow in one’s potential and the inevitability of death, are not the kinds of things a (limited, realistic) AI can have much effect on. They are part of what has been perhaps quaintly called the human condition.
To even try to describe this research problem, one has to shift linguistic registers. The existentialist and AI research traditions developed in very divergent contexts. This is one reason to believe that their ideas are new to each other, and that a synthesis may be productive. In order to accomplish this, one needs a charitably considered, working understanding of existentialism. I will try to provide one in my next post in this series.




 is the posterior probability of a hypothesis
is the posterior probability of a hypothesis  given observed data
given observed data 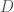 . If one is following statistically optimal procedure, one can compute this value by taking the prior probability of the hypothesis
. If one is following statistically optimal procedure, one can compute this value by taking the prior probability of the hypothesis  , multiplying it by the likelihood of the data given the hypothesis
, multiplying it by the likelihood of the data given the hypothesis  , and then normalizing this result by dividing by the probability of the data over all models,
, and then normalizing this result by dividing by the probability of the data over all models, 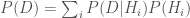 .
.
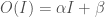 for some parameters
for some parameters 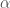 and
and  , where
, where 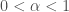 and
and  , then we can compute:
, then we can compute:
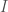 will be exponentially increasing in time
will be exponentially increasing in time  . This is the “intelligence explosion” that gives Bostrom’s argument so much momentum. The explosion only gets worse if recalcitrance is below a constant.
. This is the “intelligence explosion” that gives Bostrom’s argument so much momentum. The explosion only gets worse if recalcitrance is below a constant.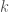 . Keep in mind that the y-axis is plotted on a log scale, which means that a roughly linear increase indicates exponential growth.
. Keep in mind that the y-axis is plotted on a log scale, which means that a roughly linear increase indicates exponential growth.

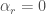 . Plugging in several values for these parameters and plotting again with the y-scale on the log axis, we get:
. Plugging in several values for these parameters and plotting again with the y-scale on the log axis, we get:
